自动化漏洞挖掘:过去、现在与未来——AI 的上限在哪里?
2025 年,我们的系统已经在主流开源仓库自动发现了超过 60 个真实世界的安全漏洞。半数以上都是高危漏洞。回顾这段历程,我反复体会到一个现象:我们之所以能走到今天,并非因为某个单一技术的突破,而是因为正确把握了 AI 演进的范式,并将最新技术与自身创新方法相结合。我们在论文阅读时也观察到,有相当一部分工作未能及时适应范式转换——即便曾在顶会发表,也逐渐因 AI 的快速发展而被边缘化。
这让我想起科学哲学家托马斯·库恩在《科学革命的结构》中提出的「范式转换」理论。库恩观察到,科学的进步并非知识的线性积累,而是经历一次次根本性的框架重构。托勒密的地心说曾经是天文学的正统范式,为了解释行星逆行等现象,天文学家们不断添加「本轮」和「均轮」,模型越来越复杂却越来越笨拙;直到哥白尼提出日心说,整个解释框架被彻底替换,那些精心构建的本轮体系一夜之间失去了意义。
AI 自动化漏洞挖掘领域正在经历类似的过程。2025 年初行之有效的方法,到 2026 年初可能已彻底被放弃——不是因为技术本身有问题,而是整个范式已经转移。理解这一点,对于把握未来方向至关重要。这一观察促使我写下这篇文章。我将系统分析自动化漏洞挖掘的技术演进历程,帮助读者把握大趋势,做出能够适应当前范式甚至跨越范式的研究,共同推动整个领域的进展。
本文将按时间线展开,分为三个部分:第一部分将简单回顾一下前 LLM 时代的漏洞挖掘方法;第二部分将详细分析 2022 至 2025 年间的自动化漏洞挖掘主流方法,并分析发生在其间的 3 次范式转变;第三部分展望自动化漏洞挖掘的未来,从而帮助大家更好地规划未来的研究。
第一部分:前 LLM 时代的自动化漏洞挖掘
在 LLM 出现之前,自动化漏洞挖掘主要依赖以下几种技术路线:Fuzzing、以静态污点分析为代表的代码分析、以及以符号执行与形式化验证为代表的形式化方法。它们各有所长,但都面临难以逾越的天花板。
Fuzzing:擅长内存安全,止步于逻辑漏洞
Fuzzing 在发现内存安全问题方面表现卓越。配合各类 Sanitizer——AddressSanitizer 检测 UAF 和溢出、ThreadSanitizer 发现数据竞争、UndefinedBehaviorSanitizer 捕获整数溢出和空指针解引用——fuzzing 已经成为发现内存 corruption 类漏洞的首选方法。AFL、libFuzzer 等覆盖率引导工具能在数小时内探索数百万条执行路径,这种自动化规模是人工审计无法企及的。Google 的 OSS-Fuzz 项目已在开源生态中发现超过一万个安全缺陷,足以说明工业界对这项技术的依赖程度。
然而,fuzzing 的局限性同样明显:
- 它本质上是语法层面的暴力搜索。对于需要满足复杂约束的输入——校验和验证、加密签名、多阶段协议状态机——变异策略极易陷入局部最优。即便引入符号执行构建混合方案,路径爆炸问题依然难以逾越。
- 更关键的是,fuzzing 依赖可观测的异常信号来判定漏洞存在。对于那些触发后不产生崩溃或异常的漏洞类型,它几乎无能为力。权限校验的缺失、业务逻辑的绕过——这些缺陷在运行时表现为「正常执行」。除非为每种漏洞类型专门设计 adapter 将其转化为 fuzzer 能捕捉的信号,但这种逐类型定制的成本很难可行。
- 随着 CFG、RFG、MTE、PAC 等缓解措施的普及,攻防格局也在改变。MTE 压缩了堆溢出的利用窗口,CFI 阻断了控制流劫持的经典路径,PAC使得间接调用劫持成本急剧上升。许多崩溃即使被发现也难以转化为可利用漏洞,从 crash 到 exploit 的鸿沟正在持续拉大。
污点分析:强于规则覆盖,困于规则边界
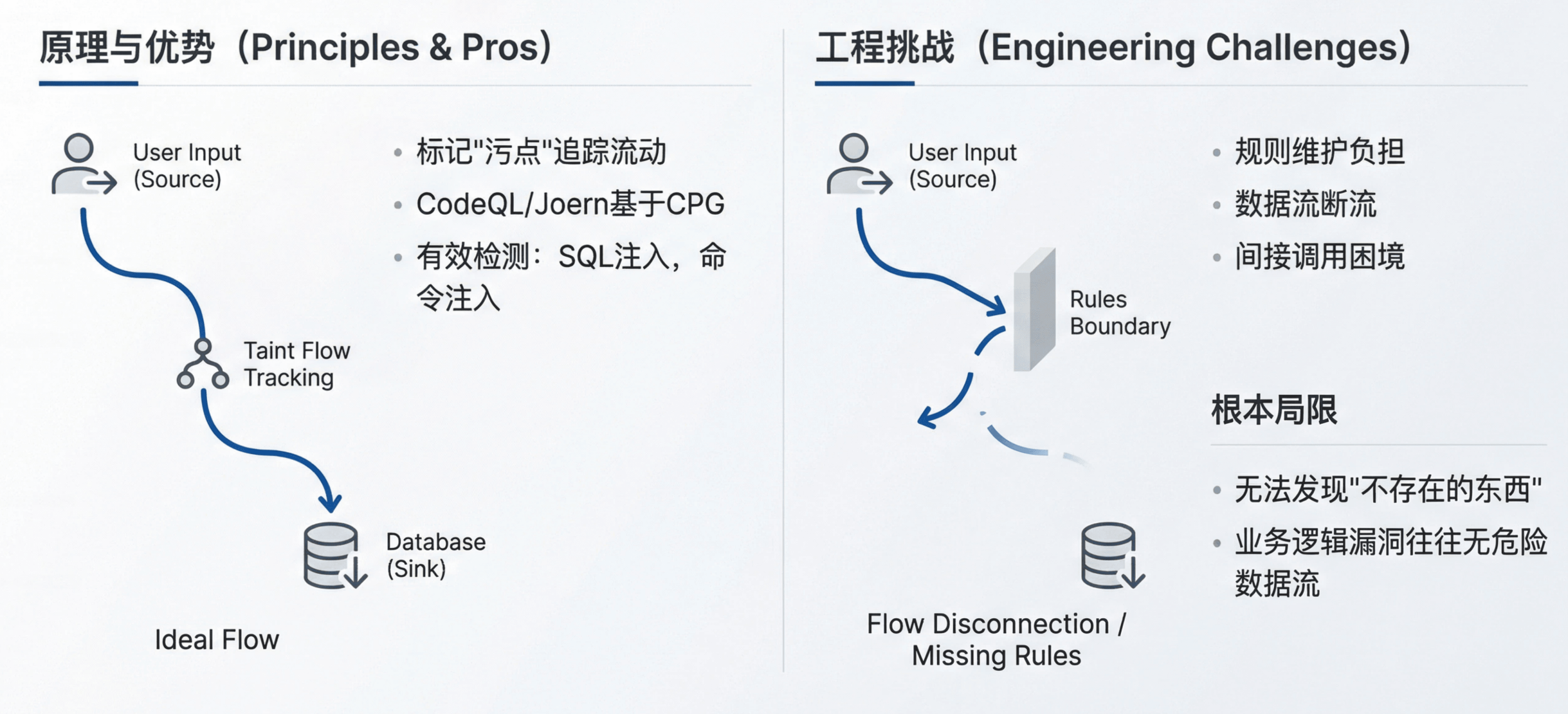
污点分析的核心思想很直观:标记不可信输入为「污点」,追踪它如何在程序中流动,当污点数据到达敏感操作时报警。CodeQL 和 Joern 等工具基于代码属性图(CPG)实现了这一范式,允许研究员用声明式查询语言描述漏洞模式。
对于模式清晰的漏洞类型——SQL 注入、命令注入、路径遍历——污点分析确实有效。用户输入是 source,数据库查询或系统调用是 sink,两者之间缺少过滤即为漏洞。这类规则容易编写,检测也相对准确。
但污点分析面临一系列工程与理论层面的挑战:
- 规则维护的持续负担:每个新框架、新 API 都需要更新 source 和 sink 定义,规则库的覆盖度直接决定检测能力的上限。
- 数据流追踪的断流问题:当污点流经复杂的库函数或大型中间函数时,分析引擎往往丢失追踪,需要为这些函数手工编写传播模型。
- 间接调用与异步流的困境:回调函数、事件驱动、跨线程通信等场景下,数据流的走向难以静态确定。
- 指针与别名分析的精度瓶颈:不精确的别名关系会沿调用链传播放大,要么导致大量误报,要么遗漏真实路径。
解决以上每一个问题都需要海量的工程投入,而这些投入往往只在特定语言、特定框架下有效。
更根本的局限在于:污点分析只能发现那些能被抽象为「source 到 sink 的数据流」的漏洞。考虑一个权限绕过场景:管理员接口本应检查用户角色,但开发者遗漏了这个检查。这里没有污点数据流向危险函数,只是缺少了一段本该存在的校验代码——污点分析无法发现「不存在的东西」。类似地,业务逻辑漏洞往往不涉及危险数据流,而是合法操作在错误的上下文中被执行。
符号执行与形式化验证:理论优雅,实践受限
符号执行试图用约束求解器探索所有可行路径,但路径爆炸问题使其难以应对真实规模的代码库。KLEE、angr 等工具在小型程序或特定模块上表现尚可,面对百万行级别的项目则力不从心。
形式化验证在协议分析、密码学实现等特定领域展现了价值——seL4 微内核的完整验证是典范——但其所需的规约编写成本和专业门槛使其难以规模化应用。
至于手工编写的特定漏洞扫描器,它们永远在追赶新的漏洞模式,本质上是将安全研究员的知识硬编码为规则,既无法泛化也难以维护。

各方法能力对比
| 方法 | 通用性 | 误报率 | 漏报率 | 自动化程度 | 计算成本 |
|---|---|---|---|---|---|
| Fuzzing | 低(主要覆盖内存安全) | 低 | 高 | 高 | 中 |
| 污点分析 | 中(强依赖规则覆盖) | 高 | 中 | 低 | 中 |
| 符号执行 | 低(受复杂度限制) | 低 | 低 | 高 | 高 |
| 形式化验证 | 低(特定领域) | 低 | 低 | 低(需规约) | 高 |
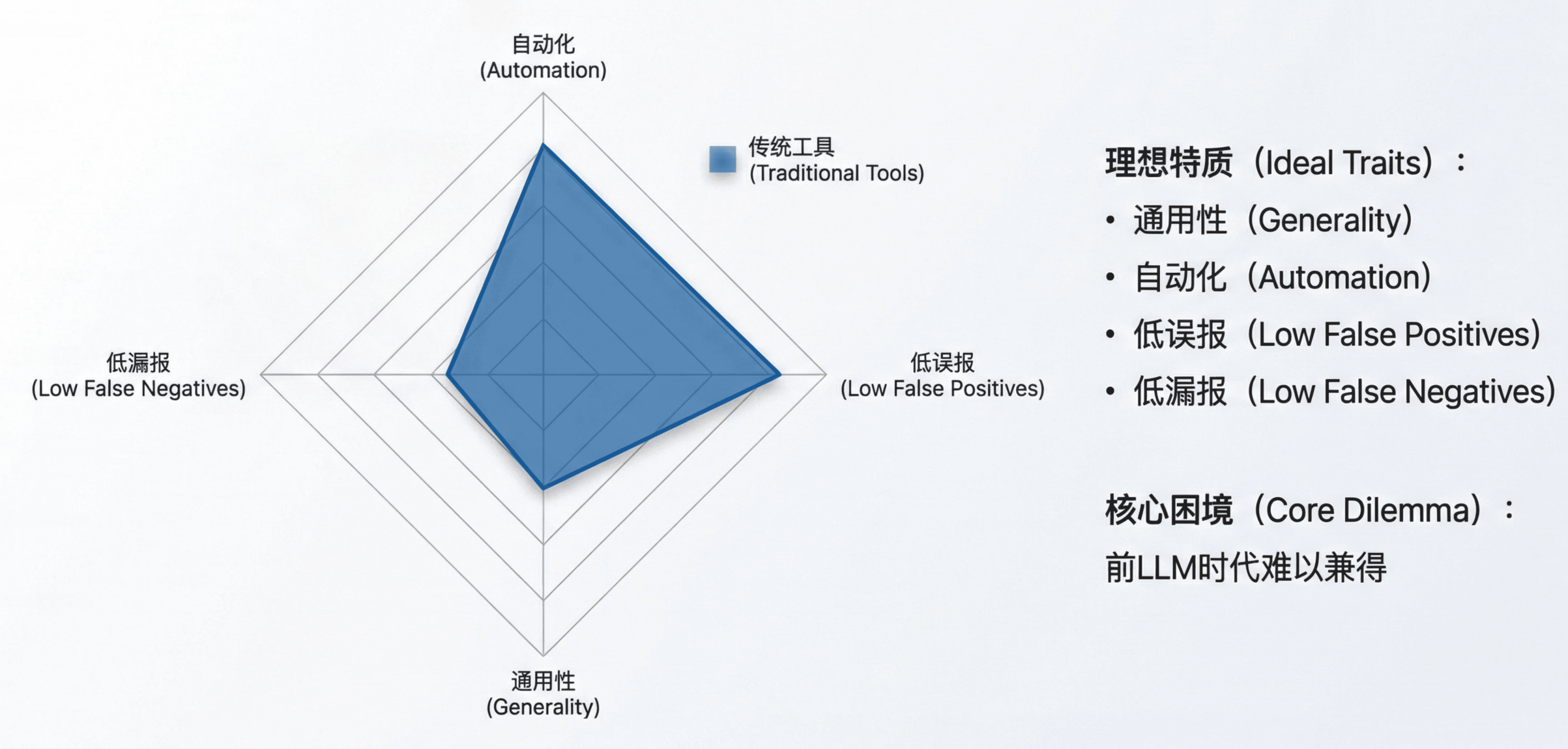
理想的自动化漏洞挖掘系统应该具备四个特质:
- 通用性:能发现各类漏洞,而非仅限于内存安全或特定框架;
- 自动化:无需为每种漏洞模式手工编写规则;
- 低误报:减少人工复核成本;
- 低漏报:不遗漏真实的安全缺陷。
这四个目标在前 LLM 时代几乎不可兼得,工具设计者总是在它们之间艰难取舍。
然而 LLM 来临之后,这一切变得可期待。
第二部分:2022–2025 —— AI 自动化漏洞挖掘的三次范式跃迁
2022 年:LLM 前夜——代码分类范式的建立
语言模型的客观特点
2022 年的语言模型以 BERT 系列为主,具有以下特征:上下文窗口极其有限(通常 512–1024 tokens),缺乏真正的推理能力,主要依赖模式匹配和特征提取。这些模型本质上是「分类器」——给定输入,输出标签。

在这一技术条件下,最自然的范式是代码分类:将代码片段输入模型,输出「有漏洞/无漏洞」的二分类结果。这与传统机器学习在安全领域的应用一脉相承,只是用 transformer 替换了之前的特征工程。
代表性工作
Thapa 等人的 Transformer-Based Language Models for Software Vulnerability Detection(2022 年 4 月)正是这一范式的典型代表。他们展示了 transformer 在 C/C++ 漏洞检测上优于 BiLSTM 和 BiGRU,这在当时是有意义的增量贡献——证明了 transformer 架构在代码理解任务上的优势。这项工作建立的实验方法论和评估基准,为后续研究奠定了基础。
历史转折点
2022 年 11 月 30 日,ChatGPT 发布。
这一事件的意义在当时被严重低估:大多数研究者仍在用 transformer 做分类,而没有意识到一个全新的范式——LLM 作为推理引擎——即将颠覆整个领域。
2023 年:识别 LLM 能力边界,寻找合适的位置
LLM 的关键变化
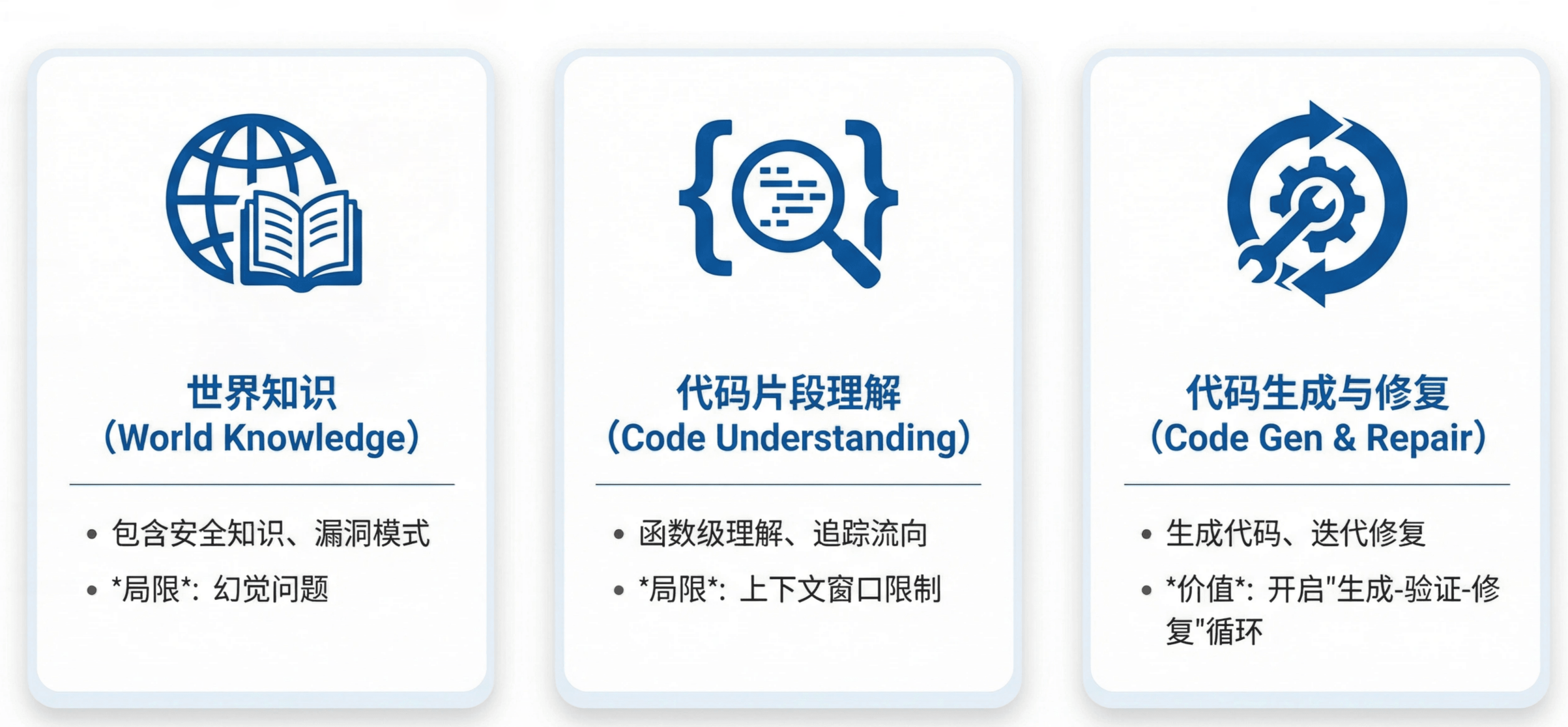
2023 年的 LLM(GPT‑3.5/4、Claude 1/2)展现出三个可被利用的核心能力:
世界知识
模型在预训练阶段吸收了大量安全相关知识,包括常见漏洞模式、危险函数列表、协议规范等。这些知识可以用于识别 source/sink、理解 RFC 文档、判断函数行为。局限在于幻觉问题——模型可能自信地给出错误信息,需要外部验证机制。代码片段理解
模型对函数级别的代码理解能力已经相当强,能够追踪变量流向、理解控制流、判断代码语义。但关键限制是无法处理仓库级分析——上下文窗口(4K–32K tokens)是硬约束,跨文件的复杂调用关系超出模型能力。有限复杂度的代码生成与迭代修复
模型能够生成结构合理的代码,更重要的是能够根据编译错误、运行时反馈进行多轮修改。这使得「生成–验证–修复」的迭代流程成为可能。
准确利用能力的工作
真正有洞察力的研究者识别了这些能力边界,并把 LLM 放在它能发挥价值的位置。
利用代码生成能力:Harness 生成方向
Google OSS-Fuzz 团队的 AI-Powered Fuzzing(2023 年 8 月)开创性地使用 LLM 生成 fuzz target。这个工作的洞察在于:不要让 LLM 做它不擅长的事(完整的漏洞检测),而是让它增强已经有效的工具(fuzzing)。
LLM 擅长理解代码结构和生成代码,这正好解决了 fuzzing 的核心瓶颈——harness 编写。编译器提供的错误反馈,使得迭代修复成为可能。
之后的一系列工作延续了这一思路:
- PromptFuzz(Lyu 等,CCS 2024,2023 年 12 月提交)使用覆盖率引导的 prompt 变异迭代生成 fuzz 驱动,在 14 个真实库上比 OSS-Fuzz 和 Hopper 分别提升 1.61 倍和 1.63 倍分支覆盖率,发现 33 个真实漏洞。
- ChatAFL(NDSS 2024)将这一模式扩展到协议 fuzzing。协议实现的测试难点在于消息需要符合特定语法和状态机——而这些信息通常只存在于自然语言的 RFC 文档中。ChatAFL 利用 LLM 的世界知识理解协议规范,生成符合协议语法的测试用例,比 AFLNet 多覆盖 47.6% 的状态转换,发现 9 个此前未知的漏洞。
- KernelGPT(2023 年 12 月)将这一模式应用于内核 fuzzing,使用 LLM 从 Linux 内核源码中提取驱动和 socket 操作处理程序,生成 syzkaller 可用的 harness。
利用世界知识和代码理解:辅助静态分析方向
LATTE(Liu 等,2023 年 10 月,TOSEM 2025)是一个 LLM 驱动的静态二进制污点分析工具。它用 LLM 替代人工知识工程:自动识别 source/sink,自动生成污点传播规则。传统污点分析工具需要安全专家手动定制这些规则,LATTE 将这一过程自动化。在真实固件中发现 37 个新漏洞,其中 7 个获得 CVE 编号。这项工作展示了 LLM 世界知识的实际价值——只要后续有静态分析工具验证,幻觉不会直接变成漏报。
GPTScan(Sun 等,ICSE 2024)采用类似思路检测智能合约逻辑漏洞。GPT 负责理解代码语义、生成静态分析约束,静态分析工具负责精确验证。这种分工让 LLM 做它擅长的事(理解代码意图),把精确分析留给传统工具。
代码分类范式的探索
与此同时,大量工作在探索用 LLM 做端到端的漏洞分类:
- Understanding the Effectiveness of Large Language Models in Detecting Security Vulnerabilities(Khare 等,2023 年 11 月)系统评估了 16 个 LLM 在 5000 个代码样本上的表现,发现平均准确率 62.8%、F1 分数 0.71,清晰地展示了当时 LLM 在代码分类任务上的能力边界。
- How Far Have We Gone in Vulnerability Detection Using Large Language Models(Gao 等,2023 年 11 月)引入 VulBench 基准,对比 LLM 和传统深度学习模型。
- GPTLens(Hu 等,2023 年 10 月)提出 auditor–critic 双角色设计来减少误报:Auditor 生成大量候选漏洞,Critic 评估其有效性。这种多角色相互制衡的设计,在后来的 Agent 系统中被广泛借鉴。
这些工作为理解 LLM 在漏洞检测中的能力和局限提供了重要的实证基础。然而,随着 LLM 能力的快速演进,「输入代码片段、输出分类结果」的框架天花板逐渐显现——它没有充分利用 LLM 与环境交互和迭代验证的能力。
2023 年的教训
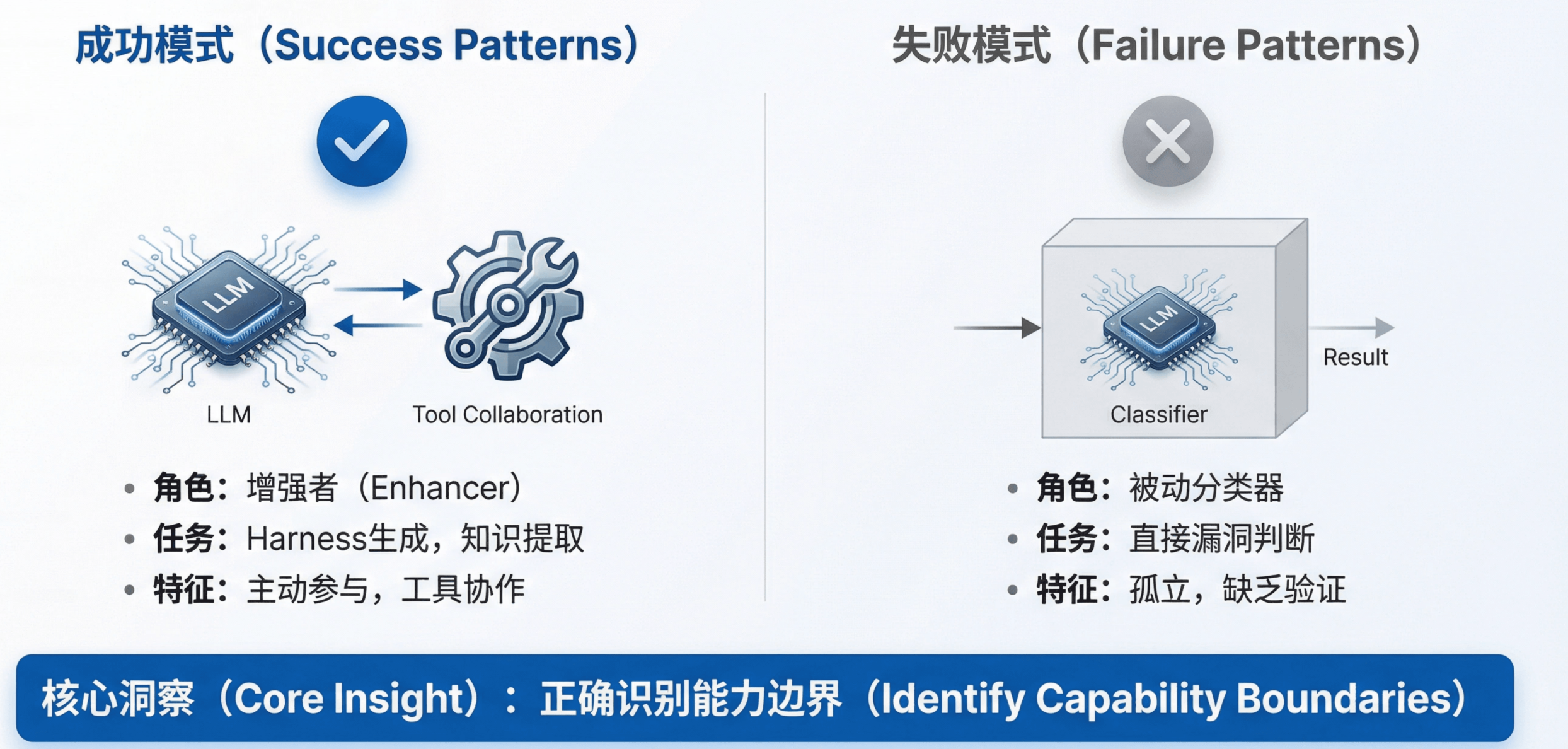
回顾 2023 年,核心教训是:成功与否取决于研究者是否正确识别了 LLM 的能力边界。
- Harness 生成工作利用了 LLM 的代码生成能力和迭代修复能力,把验证工作交给编译器和 fuzzer。
- 知识提取工作利用了 LLM 的世界知识和代码理解能力,把精确分析交给静态分析工具。
这些工作成功的原因是:LLM 在整个 pipeline 中承担它擅长的角色,其输出由可靠的外部机制验证。
相比之下,代码分类工作虽然建立了重要的评估基准,但这一范式本身存在结构性限制:它将 LLM 作为被动的判断器,而非主动的探索者。随着 Agent 范式的兴起,这一局限变得更加明显。
2024 年:Agent 前夜——旧范式的持续与新趋势的萌芽
LLM 的关键变化
2024 年是 LLM 能力显著增强的一年,四个变化对漏洞挖掘领域产生了深远影响:
上下文窗口大幅扩展
Claude 扩展到 100K+ tokens,GPT‑4 Turbo 达到 128K。这使得 Agentic 行为模式成为可能——模型可以在长对话中保持状态,记住之前的探索结果,进行多步骤复杂推理。推理能力显著增强
2024 年 9 月 12 日 o1-preview 发布标志着推理模型的成熟。模型在代码片段上的深层分析能力接近天花板,能够追踪复杂的数据流、理解微妙的逻辑错误。代码生成能力显著增强
Pass@1 明显提升,模型一次性生成正确代码的成功率大幅提高。这使 harness 生成、规则生成等任务更加可靠,不再需要大量迭代。Agent 框架快速发展
2024 年 1 月 8 日 LangChain 首个稳定版发布,Agent with Tool Use 成为工程上可行的方案。6 月 20 日 Claude 3.5 发布,真正适合 Agentic 场景的模型开始可用。8 月 1 日 LangGraph 发布,复杂 agent 工作流的编排变得更加便捷。
代码分类范式的持续探索
代码分类范式在 2024 年继续繁荣,发表了大量研究成果。随着 Agentic 范式的兴起,这一方向的很多工作逐渐被时代所淘汰,不过其中用到的一些技术组件也确实在新的范式中保留了下来。
- 多角色协作的探索:Multi-role Consensus through LLMs Discussions for Vulnerability Detection 让「测试者」和「开发者」角色辩论来做分类;LLM-SmartAudit 使用 ProjectManager、Counselor、Auditor、Programmer 四个 agent 协作做分类。这些工作看到了多角色协作的价值——这一设计理念在后来的 Agentic 系统中得到了更充分的发挥,尽管它们在代码分类框架内的应用受到了一定限制。
- 知识增强与提示工程:Vul-RAG 用知识级别的检索增强来提升分类性能;CoT prompting、DLAP 探索提示工程技巧;GRACE 用 Joern 生成 CPG 作为额外输入增强分类;SCALE 用 LLM 生成代码注释附加到 AST 再做分类。这些技术——RAG、CoT、结构化输入增强——本身具有持久的价值,在后来的 Agentic 系统中被广泛复用。
- 微调方法:M2CVD 让 CodeBERT 和 GPT 协作分类;RealVul(EMNLP 2024)和 VulLLM(ACL 2024 Findings)探索微调方法,为特定场景下的漏洞检测提供了实用方案。
代码分类范式的根本挑战在于:它把一个可以主动探索、交互验证的智能体当作被动的分类器使用。到 2024 年,LLM 已经可以调用工具、执行代码、与环境交互,这些能力在分类框架内难以充分发挥。
LLM 辅助传统工具:持续有效的方向
这一方向在 2024 年取得了实质性成果,充分利用了 LLM 增强的能力。
Fuzzing 方向
Google OSS-Fuzz 的 Leveling Up Fuzzing(2024 年 11 月)是里程碑式的工作。LLM 自动生成 fuzz harness,通过 agent 循环修复编译错误、分类崩溃结果。在 272 个 C/C++ 项目中增加 37 万+ 行新代码覆盖,发现 26 个新漏洞,包括在 OpenSSL 中存在二十年的 CVE‑2024‑9143。这项工作证明了代码生成能力增强带来的实际收益——harness 生成的成功率和质量都大幅提升。LIFTFUZZ(CCS 2024)用 LLM 生成汇编测试用例来测试二进制 lifter,在 LLVM、Ghidra、angr 等工具中发现了大量 bug;ProphetFuzz(CCS 2024)用 LLM 预测高风险的选项组合,72 小时 fuzzing 发现 364 个漏洞,获得 21 个 CVE。
静态分析方向
LLMDFA(NeurIPS 2024)是编译器无关的数据流分析框架,将问题分解为子任务,用 LLM 合成代码调用外部工具,用 tree-sitter 减少幻觉,达到 87.10% 精确率和 80.77% 召回率。IRIS 将 LLM 与 CodeQL 结合用于 source/sink 识别和误报减少;Enhancing Static Analysis for Practical Bug Detection(ACM PL 2024)用 LLM 过滤 UBITect 的结果;SmartLLMSentry 用 LLM 生成漏洞检测规则再用规则检测。
这些工作的共同洞察是:LLM 擅长语义理解和模式识别,传统工具擅长精确程序分析,两者结合可以互补短板。 这一方向在 2025 年仍然有效,尽管 Agentic 审计开始展现更大的潜力。
Agentic 审计的先声
2024 年最具前瞻性的工作来自 Google Project Zero。
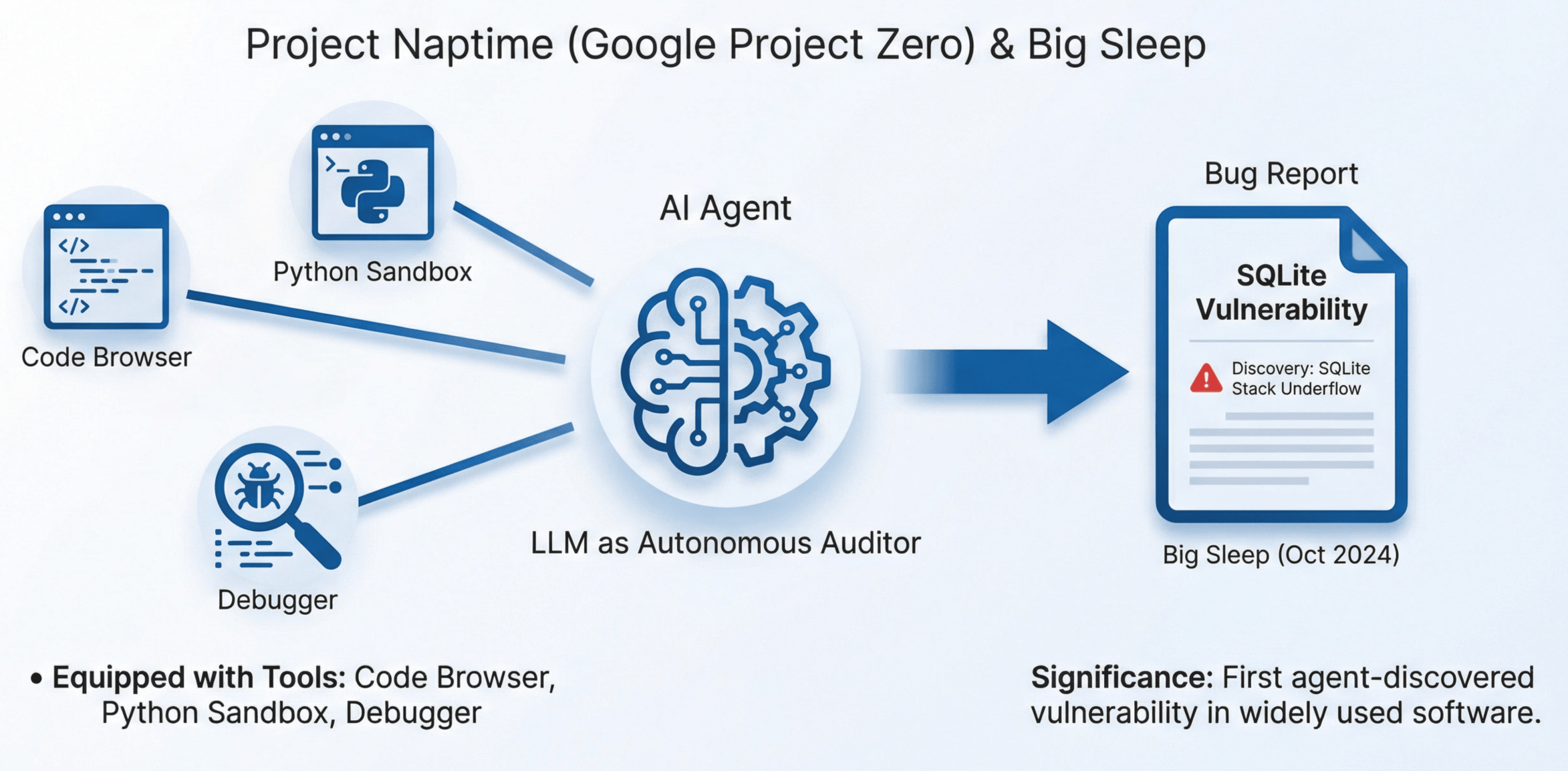
- Project Naptime(2024 年 6 月)为 LLM 配备代码浏览、Python 沙箱和调试器作为工具。LLM 制定多个安全假设并系统性测试,专注于变体分析。这是第一次正式将 LLM 定位为自主审计员——不是被动的分类器,不是传统工具的辅助,而是主动探索、形成假设、验证假设的智能体。
- From Naptime to Big Sleep(2024 年 10 月)发现了可利用的 SQLite 栈下溢漏洞。这不是通过代码分类,不是通过辅助 fuzzing,而是通过 LLM 主导的代码审计:模型理解代码、形成假设、调用工具验证、确认漏洞——完整的审计流程由 LLM 驱动。
这两项工作准确捕捉到了 Agentic 审计的趋势。这个趋势在 2025 年真正爆发。
2024 年的教训
2024 年最大的教训是:在范式转换期,识别新趋势比优化旧范式更重要。
代码分类范式的工作在技术细节上做出了有价值的贡献,许多技术(RAG、CoT、多角色设计等)在新范式中得到了继承和发展。但这些工作的整体框架在 Agent 时代到来后逐渐显得局限。
LLM 辅助传统工具是正确的方向,这些工作在 2025 年仍然有效。OSS-Fuzz 的 26 个漏洞、ProphetFuzz 的 21 个 CVE 证明了这一方向的实际价值。
真正有远见的是 Naptime 和 Big Sleep——它们准确预判了 Agentic 审计将成为下一个主战场,而这一判断在 2025 年被证实。

2025 年:Agent 时代——新范式的确立
LLM 的关键变化
2025 年的 LLM 发生了质的变化。
- 2025 年 2 月 24 日,Anthropic 发布 Claude 3.7,同日发布 Claude Code。这标志着 Agentic 能力成熟:长期规划、工具编排、自我纠错成为标准能力。模型可以自主决定下一步行动,调用合适的工具,并根据反馈调整策略。
- 2025 年 5 月 15 日,Cursor 发布 0.5 版本,支持 Background Agent。Agentic 开发被大规模使用,开发者开始习惯让 AI 自主完成复杂任务。
- 推理深度同样显著提升。模型能够进行复杂的多步骤安全分析,追踪跨函数的数据流,理解隐含的安全假设。代码理解能力接近人类专家水平,可以理解代码意图、识别异常模式、推断潜在风险。
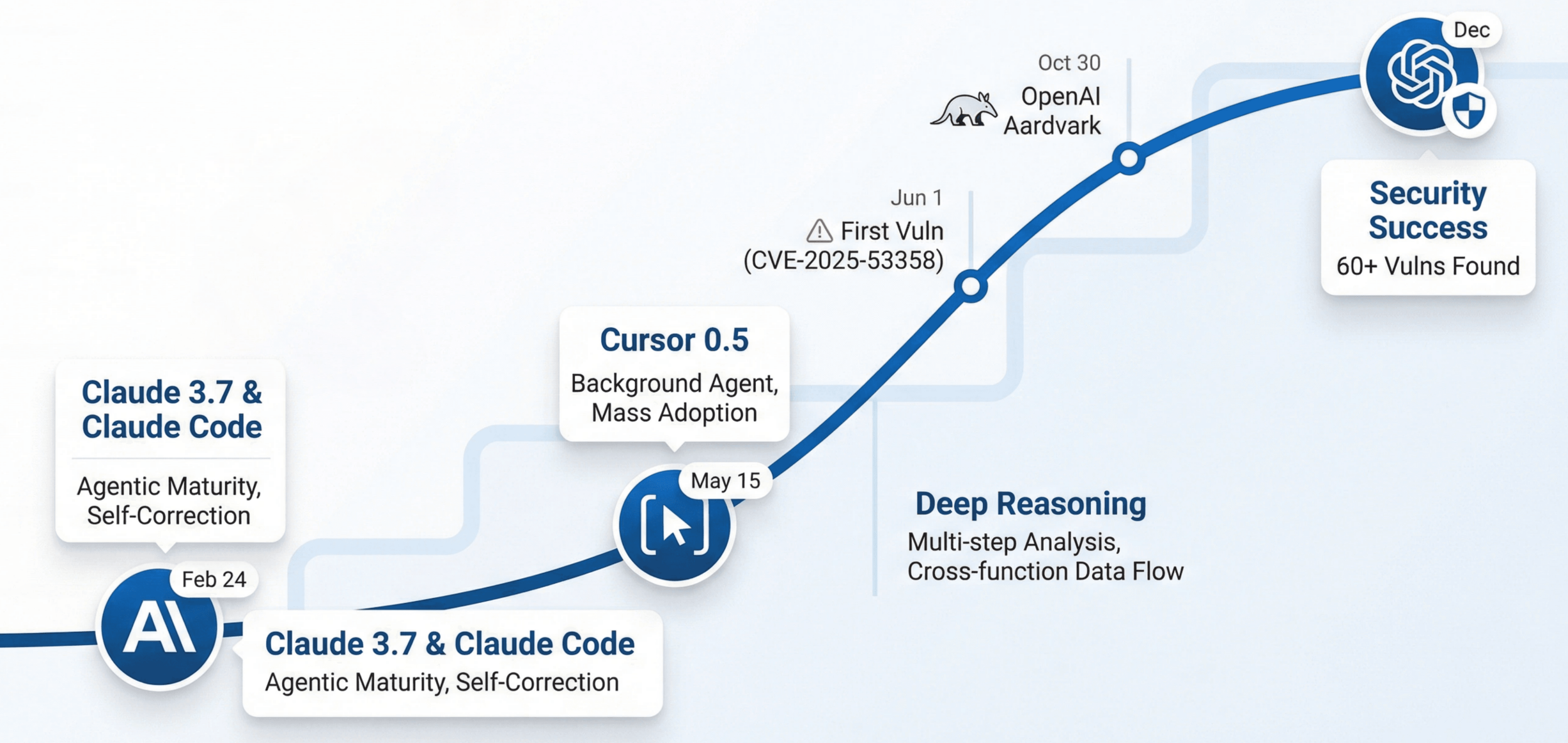
2025 年 6 月 1 日,我们的系统发现第一个漏洞 CVE‑2025‑53358——kotaemon(24k stars 的 RAG 工具)的任意文件读取漏洞。
2025 年 10 月 30 日,OpenAI 发布 Aardvark,正式进入漏洞挖掘领域。
2025 年 12 月,我们累计发现 60+ 漏洞。
范式格局的确立
到 2025 年,范式格局已经清晰:
- Agentic 代码审计成为主流方向,LLM 作为自主审计员调用工具、验证假设、迭代分析;
- LLM 辅助传统工具继续有效,特别是在 fuzzing 和静态分析领域取得实质性成果;
- 代码分类作为基础能力仍有其价值,但不再是研究前沿。
Agentic 代码审计的主流化
工业界在 2025 年全面拥抱 Agentic 审计:
- Anthropic 发布 Automated Security Reviews with Claude Code(2025 年 8 月),展示 LLM 进行自主代码审计的能力。他们的 SCONE-bench(2025 年 12 月)专门评估 LLM agent 在智能合约漏洞发现中的表现,使用 LLM 作为 controller 进行代码检查,配合可交互环境发现智能合约漏洞。
- Snyk 发布 Human + AI: The Next Era of Snyk's Vulnerability Curation(2025 年 7 月),使用 LLM 对新提交的 commit 进行 agentic 审视,配合历史漏洞 RAG 和 Web 搜索增强上下文。
- OpenAI 发布 Aardvark(2025 年 10 月),正式进入自动化漏洞挖掘领域。
学术界同样跟进:
- ACTaint(ASE 2025)使用 LLM Agent 识别 source/sink 并直接追踪数据流,检测智能合约访问控制漏洞。
- Exploring Static Taint Analysis in LLMs(ASE 2025)提出动态基准测试框架衡量 LLM 在污点分析中的能力。
LLM 辅助传统工具的深化
这一方向在 2025 年继续取得实质性成果。
Fuzzing 方向
DARPA AIxCC 竞赛催生了多个重量级系统。Trail of Bits 开源的 Buttercup(2025 年 8 月)获得竞赛第二名,使用 LLM 生成种子和补丁,发现并修复了真实开源项目中的漏洞;All You Need Is A Fuzzing Brain(2025 年 9 月)获得竞赛第四名,使用 LLM 作为 fuzzing 编排器,采用 CWE-based prompting 引导输入生成朝向特定漏洞类型,自主发现 28 个漏洞(包括 6 个 0‑day)并成功修复 14 个。deepSURF(IEEE S&P 2025)使用 LLM 为复杂 Rust API 交互生成 harness;Unlocking Low Frequency Syscalls in Kernel Fuzzing with Dependency-Based RAG 使用 LLM 生成低频系统调用测试种子,配合 syzkaller 进行内核 fuzzing。
静态分析方向
LLM-Driven SAST-Genius: A Hybrid Static Analysis Framework使用 LLM 将 Semgrep 误报从 225 个压缩到 20 个(减少 91%),并生成 exploit 验证漏洞。QLPro: Automated Code Vulnerability Discovery 使用 LLM 生成 source/sink 识别规则和 CodeQL 规则,在 10 个开源项目中检测到 41 个漏洞(CodeQL 只检测到 24 个),发现 6 个未知漏洞,其中 2 个确认为 0‑day。STaint(ASE 2025)使用 LLM 识别 source/sink 并进行双向污点分析,检测 PHP 应用中的二次漏洞;Artemis: Toward Accurate Detection of Server-Side Request Forgeries(OOPSLA 2025)使用 LLM 辅助过程间路径敏感污点分析,在 250 个 PHP 应用中发现 106 个真实 SSRF 漏洞,其中 35 个是新发现的,24 个获得 CVE。
AutoBug(OOPSLA 2025)使用 LLM 增强符号执行约束求解,提出基于路径分解的推理方法,使小模型也能在消费级硬件上进行有效分析;Towards More Accurate Static Analysis for Taint-style Bug Detection in Linux Kernel(ASE 2025)使用 LLM 减少 CodeQL 和 Suture 等传统工具的误报。
仍在旧范式中的工作
一些 2025 年发表的工作仍沿用代码分类框架。这些工作在技术上做出了贡献,但其核心范式已不再是研究前沿。
- LLMxCPG(USENIX Security 2025)用 LLM 生成 CPG 查询来做代码切片,再对切片后的代码进行二分类。其创新在于切片方法更加智能,能够为 LLM 提供更丰富的上下文信息,从而提升漏洞识别的准确性,对代码分类范式的能力边界有一定拓展。然而,本质上仍在代码分类范式内运作。随着 Agent 成本的持续下降,这类方法的相对重要性将逐渐减弱,但其中通过 CPG 进行上下文裁剪的技术本身,未来有可能被 Agent 所继承。
- Context-Enhanced Vulnerability Detection Based on Large Language Model 用程序分析提取抽象特征(API 调用、分支条件等),然后让 LLM 对这些抽象特征做分类,其特征抽象方法在新范式下同样可以作为上下文增强的手段。
- R2Vul: Learning to Reason about Software Vulnerabilities with Reinforcement Learning 用强化学习蒸馏使 1.5B 的小模型达到大模型水平,对资源受限场景下的部署具有实际意义。
- Agent4Vul 把智能合约转成注释和向量,训练多模态分类器,其多模态表示学习的思路值得借鉴。
这些工作的技术贡献可以在新范式中得到复用,但整体框架——「输入代码片段、输出分类标签」——已经不是最有效利用 LLM 能力的方式。在 LLM 已经可以主动探索代码库、调用工具验证假设的 2025 年,将其作为被动分类器使用,未能充分发挥其潜力。
持续有效的核心投入:知识工程
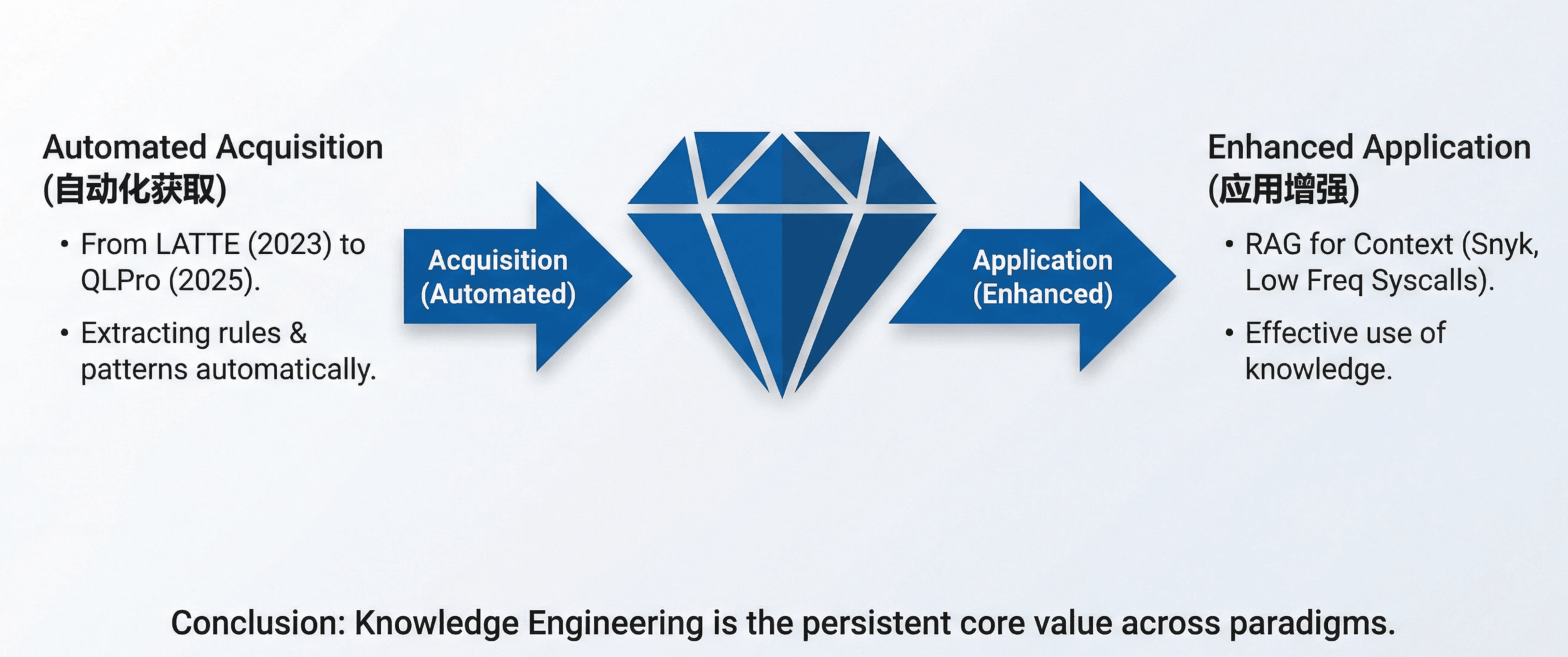
无论范式如何变化,知识工程始终是核心价值点:
- 知识获取自动化:从 LATTE(2023)用 LLM 从文档中提取检测规则,到 QLPro(2025)用 LLM 生成 CodeQL 规则,用 LLM 自动获取领域知识的方向一直有效。漏洞模式、安全最佳实践、API 使用规范——这些过去需要专家手写的知识,现在可以通过 LLM 自动提取。
- 如何更好地应用知识:Snyk 使用历史漏洞 RAG 增强上下文,Unlocking Low Frequency Syscalls 使用 Dependency-Based RAG 生成测试种子,都体现了通过 RAG 等技术可以让 LLM 表现得更好。无论是辅助工具还是 Agentic 审计,如何在上下文中送入正确的知识都是值得长期研究的问题。
2025 年的洞察
- 执行变得廉价:让 LLM 生成代码、执行测试、迭代修复的成本已经极低,这使得大规模自动化审计成为可能。
- 知识是真正的瓶颈:漏洞模式、安全最佳实践、领域专业知识——这些才是稀缺资源。模型的推理能力已经足够强,但如果不知道「该找什么」,再强的推理也无用武之地。
- Agent 是知识的载体:通过工具调用,LLM 可以获取、验证和应用知识。Agent 不仅仅是执行器,更是将知识转化为行动的桥梁。
第三部分:未来展望——执行变得廉价,范式仍在演化
执行变得廉价,问题是要做什么
2025 年,一个深刻的变化正在发生:执行代码的成本和生成代码的成本都在急剧下降。
想象一下,三年前让 LLM 写一个完整的 fuzz harness,可能需要反复调试十几轮;今天,一次生成就能编译通过的概率已经大幅提升。三年前跑一轮大规模 fuzzing 需要精打细算云计算预算;今天,同样的预算可以覆盖十倍的测试规模。
当「能不能做」不再是问题,真正的瓶颈就变成了「要做什么」。工具在手,方向在哪? 这个问题的答案,决定了谁能在下一轮竞争中胜出。
看清方向,比埋头苦干更重要
基础模型的能力提升还没有停下来。模型越来越强,价格越来越低,但与此同时,范式的有效周期也越来越短。
这意味着什么?一个残酷的现实是:你今天开始的研究项目,可能在完成之前就已经被新范式淘汰。2023 年有人花一年时间精心设计代码分类器的特征工程,2024 年底 Agentic 审计兴起后,这些工作的价值就大打折扣。不是技术不好,而是范式变了。
因此,选择方向的能力,正在变得比执行能力更稀缺。我们需要回答三个问题:
- AI 在持续变化中,什么是不变的?
- 下一个范式会往哪里转移?
- 什么样的投入能够跨越范式、持续产生价值?
短期:Agent 编排仍是高杠杆方向
在模型能力趋同的当下,Agent 与 Agent 之间的差距可以有多大?
答案是:比人与狗的差距还大。
同样是 Claude 4.5,一个设计拙劣的 Agent 可能项目规模稍大一点就无法完成;而 Cursor 却展示了,一个精心编排的 Agent 系统,可以持续运行超过 1 周,并从零开始写出一个 100 万行代码的浏览器。差距不在模型,在编排。
工具集怎么设计?多 Agent 如何协作?反馈循环怎么构建?错误恢复机制如何实现?这些工程层面的决策,往往决定了系统能力的上限。在基础模型能力趋于同质化的今天,编排能力可以极大提升 Agent 的上限。
长期:持续学习将重塑 Agent 范式
但当前的 Agent 有一个根本性的局限:它们不会学习。
人类在反复做一类事情时,会越做越熟练,甚至触类旁通——修过十个 SQL 注入漏洞后,第十一个往往一眼就能看出来。而现在的 AI Agent 恰恰相反:随着对话的推进、上下文的膨胀,它们反而会变得越来越「笨」。长上下文不是让模型更聪明,而是让模型更迷糊。
这是近两年 AI 圈重点关注的研究方向。无论是通过模型外部的知识库和上下文管理,还是通过模型架构本身的革新,一旦在持续学习上取得突破,影响将是颠覆性的。
想象一下:一个 Agent 在审计了一百个项目后,积累了对常见漏洞模式的「直觉」;它能记住上周在类似代码库中踩过的坑;它知道哪些告警通常是误报、哪些值得深挖。
这样的 Agent,和现在「每次对话都从零开始」的 Agent,其能力将会有根本性的改变。
持续学习问题的突破,必然会引发 Agent 设计范式的变革。
AI 的上限在哪里?
从 2022 年到 2025 年,我们见证了三次范式跃迁:从「LLM 做代码分类」,到「LLM 辅助传统工具」,再到「LLM 作为自主 Agent」。每一次跃迁,都把能力边界往外推了一大步。
那么,当前的边界在哪里?
- 上下文理解的深度仍然有限。 尽管上下文窗口已经扩展到百万 token 级别,但模型真正理解一个复杂代码库全局状态的能力,还远未达到人类专家的水平。它可以「看到」所有代码,但不一定能把握代码之间的微妙关联。
- 领域知识的稀缺同样是瓶颈。 对于新兴协议、新硬件特性、罕见漏洞类型,模型的训练数据天然不足。这时候,仍然需要通过精心设计的提示词、RAG、知识库来激活模型的相关知识、抑制幻觉。知识工程的价值,在这些「边缘场景」中尤为突出。
但请注意:这些都是技术障碍,不是原理性限制。
路径爆炸曾经被认为是符号执行的「原理性限制」,但今天我们用 LLM 来选择性探索路径,部分绕过了这个问题;上下文长度曾经被认为是 transformer 的「原理性限制」,但今天百万 token 的上下文已经成为现实。技术障碍的特点是:它们会被突破,只是时间问题。
随着模型能力的提升、工具集成的深化、知识库的积累,乃至 AI 架构的持续演进,AI 在漏洞挖掘中的能力边界将不断外扩。
AGI,有很大概率会真正实现。
而媲美人类专家的自动化漏洞挖掘系统,同样有很大概率会真正实现。也许不是明年,也许不是后年,但它正在来的路上。
后记:2026 年 2 月,Anthropic 发布的 Claude Opus 4.6 在内部红队测试中自动发现了超过 500 个零日漏洞,进一步验证了本文的核心观点——AI 在自动化漏洞挖掘领域的能力边界正在快速外扩。关于这一事件的详细分析,请参阅《Opus 4.6 的 500 个 0day,对我们来说意味着什么?》。
结语
过去三年的发展给我们的最大启示是:游戏规则在快速改变。
研究的回报模式正在变化。一年前的 state-of-the-art,今天可能已经不再是最优解,因为底层范式已经转移。在这样的环境下,理解趋势、预见范式变得越来越重要;关注实际效果,而非仅仅追求论文发表,也变得越来越重要。我们能靠系统自动发现 60+ 个真实漏洞,是因为我们做工作并不是为了写论文,而是因为追问一个长期的问题:什么真正有效?
最后,感谢一路同行的同事与合作伙伴,也希望这篇文章能帮助你在接下来的几年里,做出更顺应范式、甚至引领范式的研究与工程决策。