Automated Vulnerability Discovery: Past, Present and Future — Where Are the Limits of AI?
By 2025, our system had automatically discovered more than 60 real‑world security vulnerabilities. Half of them are high-risk vulnerabilities. Looking back over this journey, I keep circling back to one observation: our progress did not come from a single breakthrough technique, but from correctly tracking paradigm shifts in AI, and consistently combining the latest capabilities with our own research methodology. As we read the literature, we also saw a pattern: a non‑trivial amount of high‑profile work failed to adapt to paradigm shifts in time—papers that once appeared at top venues gradually lost value as AI evolved.
This reminds me of Thomas Kuhn’s The Structure of Scientific Revolutions and his notion of “paradigm shifts.” Kuhn argued that scientific progress is not a linear accumulation of knowledge, but a sequence of radical restructurings of the underlying framework. Ptolemy’s geocentric model was once the orthodox paradigm; to explain retrograde motion and other anomalies, astronomers kept adding epicycles and deferents, making the model ever more complex yet increasingly fragile—until Copernicus proposed the heliocentric model and the entire explanatory framework was replaced. The meticulously built epicycle system lost its meaning almost overnight.
AI‑driven automated vulnerability discovery is undergoing a similar process. Methods that worked well in early 2025 could be abandoned by early 2026—not because the techniques are “wrong,” but because the dominant paradigm has shifted. Understanding this is crucial if you care about future directions. That realization is what led me to write this article: to systematically analyze how automated vulnerability discovery has evolved, help readers see the big picture, and design research that not only fits the current paradigm but has a chance of carrying across paradigms.
We will follow a rough timeline and split the discussion into three parts: Part 1 briefly revisits pre‑LLM approaches to vulnerability discovery; Part 2 looks closely at mainstream methods from 2022 to 2025 and the three major paradigm shifts that occurred during this period; Part 3 looks ahead to the future of automated vulnerability discovery and what it implies for your next few years of research.
Part 1: Before LLMs — What Traditional Automation Could and Couldn’t Do
Before LLMs, automated vulnerability discovery mainly followed three technical routes:
- Fuzzing
- Static code analysis, typified by taint analysis
- Formal methods, typified by symbolic execution and formal verification
Each had strengths, but all hit hard ceilings.
Fuzzing: Great at Memory Safety, Weak on Logic Bugs
Fuzzing is outstanding at uncovering memory‑safety issues. Combined with sanitizers—AddressSanitizer for UAF and overflows, ThreadSanitizer for data races, UndefinedBehaviorSanitizer for integer overflows and null dereferences—fuzzing has become the de‑facto method for discovering memory‑corruption vulnerabilities. Coverage‑guided fuzzers such as AFL and libFuzzer can explore millions of execution paths within hours, a scale of automation humans simply cannot match. Google’s OSS‑Fuzz has discovered over ten thousand security issues in the open‑source ecosystem, illustrating the industry’s reliance on this technique.
But fuzzing has sharp limitations:
- At its core, it is syntactic brute‑force search. For inputs that must satisfy complex constraints—checksums, cryptographic signatures, multi‑stage protocol state machines—mutation strategies tend to get trapped in local optima. Even when you mix in symbolic execution, path explosion remains a hard barrier.
- More fundamentally, fuzzing relies on observable abnormal signals—crashes, OOMs, ASan violations—to flag potential vulnerabilities. For issues that do not manifest as crashes, fuzzing is nearly blind. Missing permission checks and business‑logic flaws look like “normal execution” at runtime. You can try to design custom oracles and adapters to transform such vulnerabilities into fuzzer‑detectable signals, but doing that per vulnerability type does not scale.
- As mitigations such as CFI, RFG, MTE, and PAC proliferate, the offense/defense balance also shifts. MTE shrinks the window for exploiting heap overflows; CFI blocks classic control‑flow hijacks; PAC makes pointer hijacking significantly more expensive. Many crashes, even when found, can no longer be turned into practical exploits. The gap from crash to exploit keeps widening.
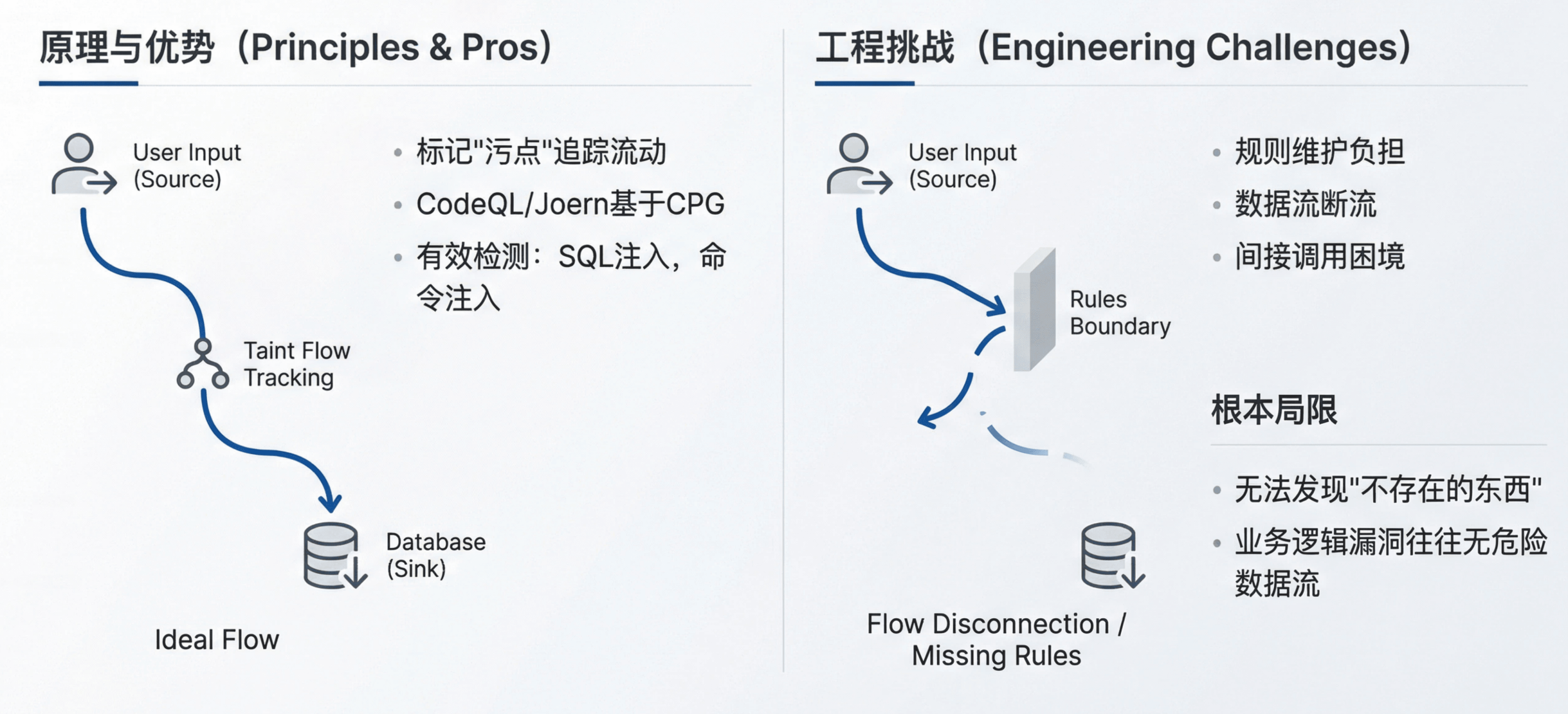
Taint Analysis: Strong Within Rules, Trapped by Rule Boundaries
The idea behind taint analysis is intuitive: mark untrusted inputs as “tainted,” track how they flow through the program, and raise an alert when tainted data reaches a sensitive sink. Tools like CodeQL and Joern implement this paradigm over code property graphs (CPGs) and let researchers describe vulnerability patterns with declarative queries.
For vulnerability classes with clean patterns—SQL injection, command injection, path traversal—taint analysis is genuinely effective. User input is the source; database queries or system calls are the sinks; missing sanitization in between is the bug. The rules are easy to write, and detection is reasonably accurate.
But taint analysis faces both engineering and theoretical challenges:
- Ongoing rule maintenance: every new framework and API requires updates to source/sink definitions. Coverage of this rule set largely determines the ceiling of your detection capability.
- Data‑flow gaps: when taint passes through large helper functions or complex libraries, engines often lose track and need hand‑written propagation models.
- Indirect calls and asynchronous flows: callbacks, event‑driven architectures, and cross‑thread communication make data‑flow paths hard to determine statically.
- Pointer and alias analysis limits: imprecise aliasing blows up along call chains, leading either to massive false positives or missed real paths.
Fixing each of these demands huge engineering investment, often bound to specific languages and frameworks.
More fundamentally, taint analysis can only find vulnerabilities that can be phrased as “data flows from source to sink.” Consider a missing authorization check: an admin‑only API is implemented without verifying user roles. There is no dangerous data flowing to a sink; the problem is that a crucial check is absent. Taint analysis is not designed to detect “things that aren’t there.” Many business‑logic flaws fall into this category: they come from valid operations being executed in invalid contexts, rather than from dangerous data flows.
Symbolic Execution and Formal Verification: Elegant in Theory, Hard in Practice
Symbolic execution tries to explore all feasible paths via constraint solving, but path explosion makes it impractical for real‑world codebases. Tools such as KLEE and angr do well on small programs or specific modules, but struggle with million‑line projects.
Formal verification has shown strong value in specialized domains such as protocol analysis and critical cryptographic implementations—seL4’s complete verification is the canonical example—but the cost and expertise required to write specifications at scale make it difficult to deploy widely.
Custom, hand‑written scanners are yet another route: encoding expert knowledge as rules for specific vulnerability types. These inevitably chase the latest patterns, rarely generalize, and are expensive to maintain.

Comparing Capabilities
| Method | Generality | False Positives | False Negatives | Automation | Compute Cost |
|---|---|---|---|---|---|
| Fuzzing | Low (mostly memory safety) | Low | High | High | Medium |
| Taint analysis | Medium (rule‑coverage dependent) | High | Medium | Low | Medium |
| Symbolic execution | Low (complexity constrained) | Low | Low | High | High |
| Formal verification | Low (narrow domains) | Low | Low | Low (needs specs) | High |
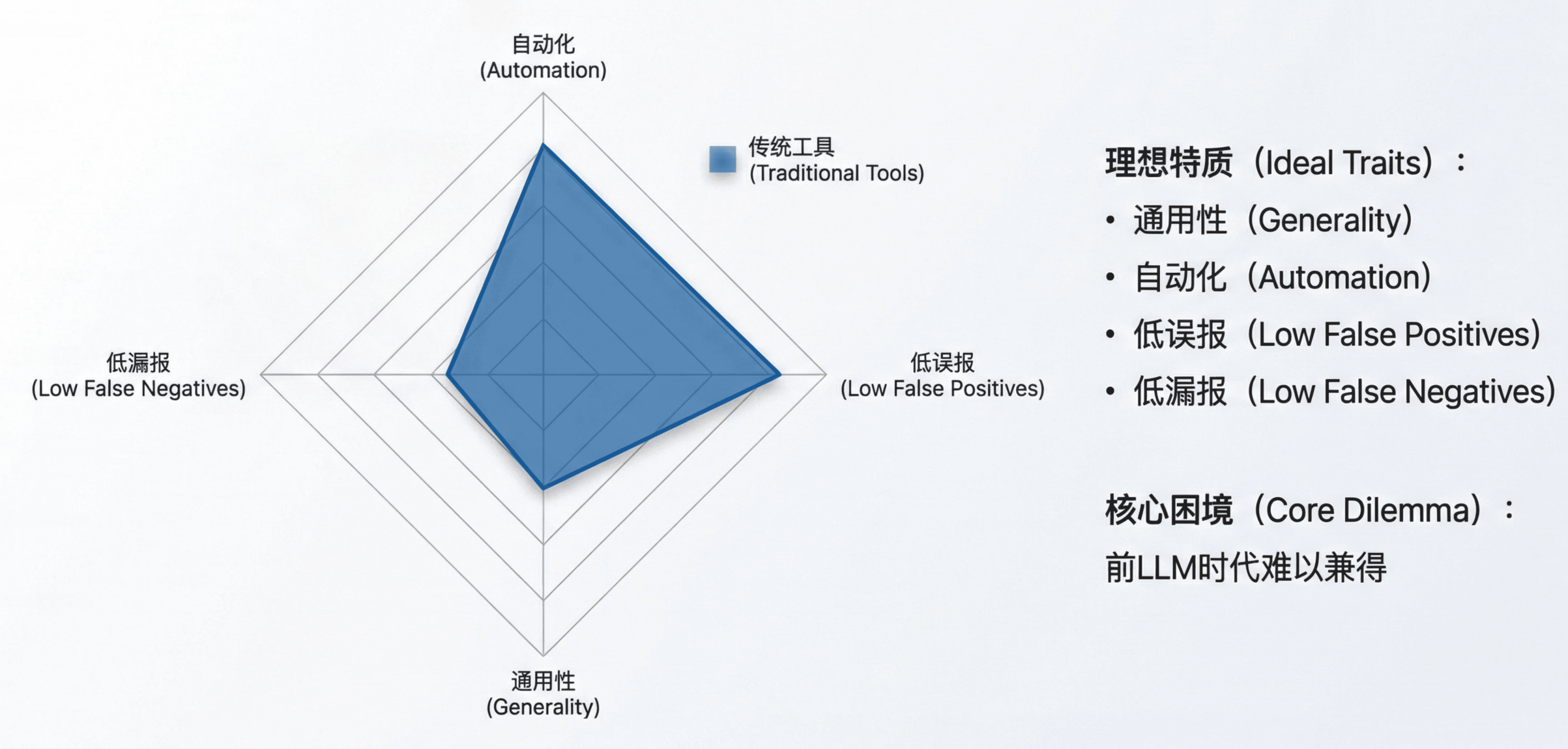
An ideal automated vulnerability‑discovery system would have four properties:
- General — can find many bug classes, not just memory safety or a single framework
- Automated — does not require hand‑written rules for each pattern
- Low false positive rate — keeps human triage costs down
- Low false negative rate — misses as few real vulnerabilities as possible
In the pre‑LLM era, these four were nearly impossible to achieve at once; tool designers constantly had to trade one dimension for another.
With LLMs, this picture started to change.
Part 2: 2022–2025 — Three Paradigm Shifts in AI‑Driven Vulnerability Discovery
2022: The Pre‑LLM Night — Establishing the Code‑Classification Paradigm
What Language Models Could Actually Do
In 2022, mainstream models were BERT‑like encoders with very limited context windows (typically 512–1024 tokens) and little real reasoning capacity. They excelled at pattern matching and feature extraction. Functionally, they were classifiers: take an input, output a label.

Given those constraints, the natural paradigm was code classification: feed code snippets, get a “vulnerable / not vulnerable” label. This extended prior ML‑based vulnerability detection, simply replacing hand‑crafted features with transformers.
Representative Work
Thapa et al.’s Transformer‑Based Language Models for Software Vulnerability Detection (April 2022) is a canonical example. It showed that transformers beat BiLSTM and BiGRU on C/C++ vulnerability datasets—an important incremental result at the time, validating transformers as strong encoders for code understanding. Its experimental methodology and benchmarks seeded later work.
A Quiet Turning Point
On November 30, 2022, ChatGPT was released.
The importance of this event was massively underestimated at the time. Most researchers were still using transformers as classifiers, without realizing that a new paradigm—LLMs as reasoning engines and tool‑using agents—was about to reshape the field.
2023: Mapping LLM Boundaries and Finding the Right Roles
Key Changes in LLMs
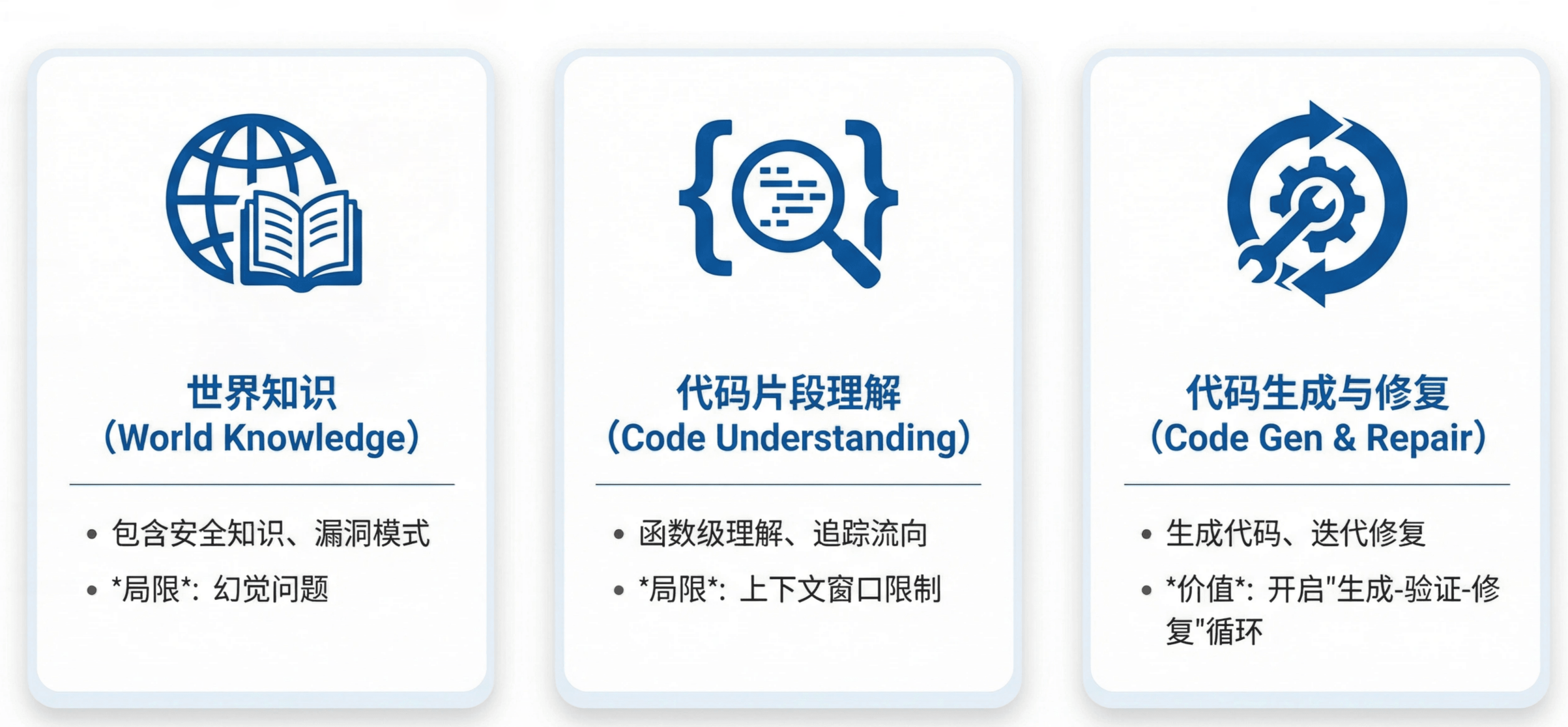
By 2023, models such as GPT‑3.5/4 and Claude 1/2 had three exploitable capabilities:
World Knowledge
Pretraining exposed them to a large amount of security‑relevant information: vulnerability patterns, dangerous APIs, protocol specifications, etc. They can identify sources/sinks, parse RFCs, and reason about function behavior. The downside is hallucinations, which necessitate external verification.Strong Function‑Level Code Understanding
At the scale of functions, LLMs can follow data flow, understand control flow, and reason about semantics. But they are still bounded by context windows (4K–32K tokens) and struggle with whole‑repo, multi‑file analysis.Moderately Reliable Code Generation and Iterative Repair
They can generate structurally sound code and, crucially, fix it iteratively based on compiler errors and runtime feedback. This makes “generate → run → fix” loops viable.
Work That Used These Capabilities Well
The more insightful researchers recognized these boundaries and placed LLMs where they shine.
Harness Generation: Leaning into Code Synthesis
Google OSS‑Fuzz’s AI‑Powered Fuzzing (August 2023) was a seminal work that used LLMs to generate fuzz harnesses. The key insight: do not ask LLMs to solve end‑to‑end vulnerability detection; instead, let them unblock bottlenecks in tools that already work, like fuzzers.
LLMs are good at reading code and writing code. That is exactly the bottleneck in fuzzing: writing high‑quality harnesses. Compiler diagnostics make iterative repair straightforward.
Follow‑up work extended this:
- PromptFuzz (Lyu et al., CCS 2024; submitted Dec 2023) used coverage‑guided prompt mutation to iteratively synthesize fuzz drivers. Across 14 real‑world libraries it achieved 1.61× and 1.63× higher branch coverage than OSS‑Fuzz and Hopper, and found 33 real bugs.
- ChatAFL (NDSS 2024) extended the idea to protocol fuzzing. Protocol implementations are hard to fuzz because valid inputs must obey complex grammars and state machines encoded only in text RFCs. ChatAFL leveraged LLM world knowledge to read specs and synthesize valid test inputs, covering 47.6% more state transitions than AFLNet and finding 9 previously unknown vulnerabilities.
- KernelGPT (Dec 2023) applied the same pattern to kernel fuzzing, using LLMs to extract driver and socket‑handling code from the Linux kernel and emit harnesses compatible with syzkaller.
Extracting Knowledge and Enhancing Static Analysis
LATTE (Liu et al., submitted 2023‑10, to appear in TOSEM 2025) is an LLM‑driven static taint analyzer for binaries. It replaces manual knowledge engineering with an LLM that identifies sources/sinks and generates taint‑propagation rules. Traditional taint analyzers needed experts to handcraft these; LATTE automates the process. It found 37 new vulnerabilities in real firmware, including 7 assigned CVEs. The lesson: LLM hallucinations are acceptable as long as a precise static analyzer sits downstream and filters out bogus rules.
GPTScan (Sun et al., ICSE 2024) took a similar approach for smart‑contract logic bugs: GPT handles semantic understanding and generates analysis constraints; static analysis carries out exact checking. LLMs do what they are good at—understanding code intent—while traditional tools handle precision.
The Code‑Classification Line of Work
In parallel, many papers explored end‑to‑end classification with LLMs:
- Understanding the Effectiveness of Large Language Models in Detecting Security Vulnerabilities (Khare et al., 2023‑11) evaluated 16 LLMs on 5,000 code samples, finding an average accuracy of 62.8% and F1 of 0.71, giving a clear empirical picture of capabilities and limits at that time.
- How Far Have We Gone in Vulnerability Detection Using Large Language Models (Gao et al., 2023‑11) introduced the VulBench benchmark, comparing LLMs with earlier deep‑learning models.
- GPTLens (Hu et al., 2023‑10) proposed an auditor–critic design: one role over‑flags potential bugs; another evaluates them to reduce false positives. This multi‑role pattern later became standard in agentic systems.
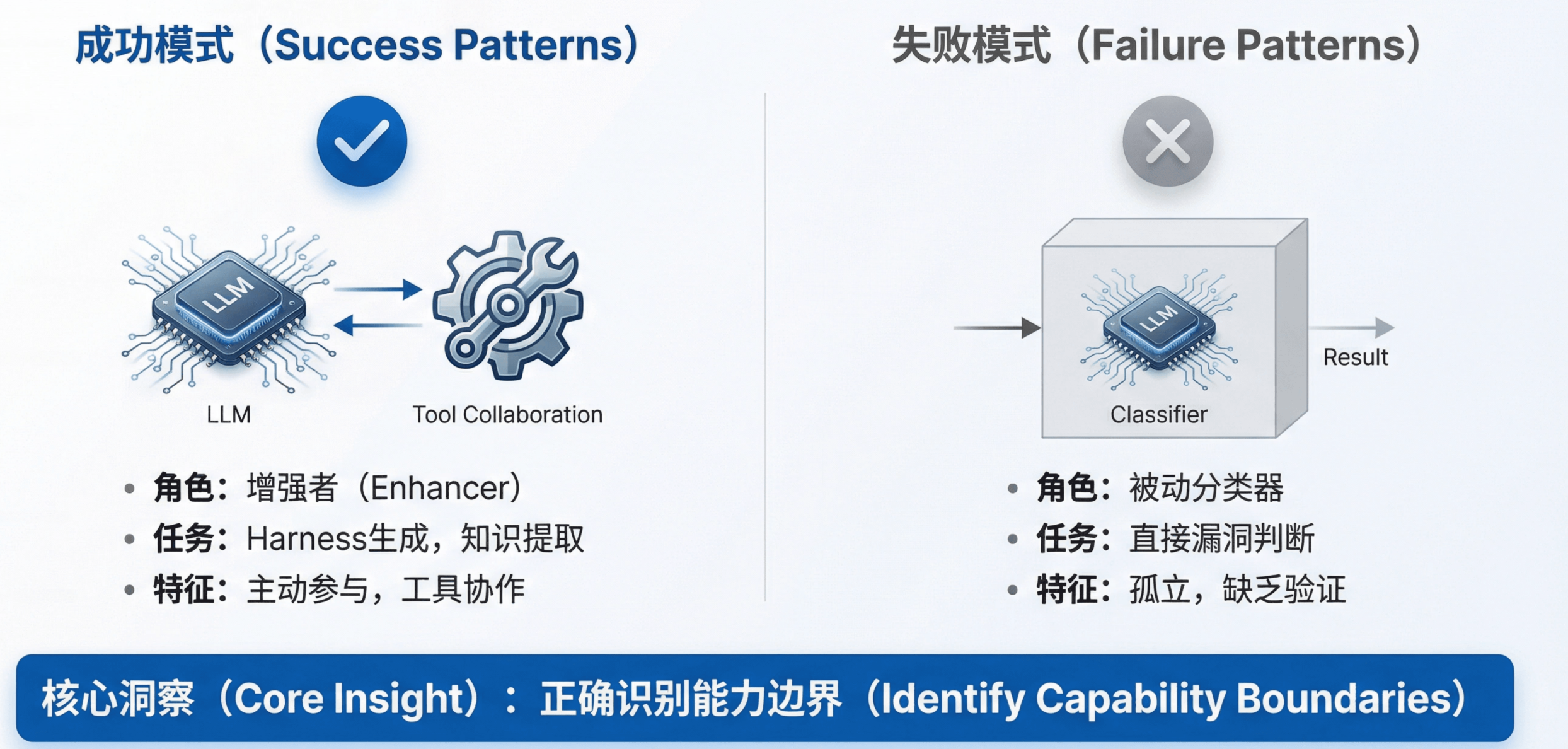
These works were valuable in mapping what LLMs could and could not do. But as LLM capabilities grew, the ceiling of “feed code, get label” became apparent: it treats models as passive judges instead of active explorers that can interact with tools and environments.
The 2023 Takeaway
The key lesson from 2023: success depends on whether you place LLMs in roles aligned with their strengths and back them with trustworthy external systems.
- Harness‑generation systems leveraged LLMs’ code synthesis and iterative repair abilities, delegating correctness to compilers and fuzzers.
- Knowledge‑extraction systems leveraged LLM semantics and world knowledge, delegating precision to static analyzers.
Classification‑only setups, despite building important benchmarks, locked LLMs into a passive role that underused their emerging interactive abilities.
2024: The Eve of Agents — Old Paradigms Persist, New Ones Emerge
Key Changes in 2024 LLMs
Four developments in 2024 had deep implications for vulnerability discovery:
Much Larger Context Windows
Claude reached 100K+ tokens, GPT‑4 Turbo 128K. This made agentic behaviors realistically usable: models could maintain state across long sessions, remember previous explorations, and perform multi‑step reasoning.Significantly Better Reasoning
The o1‑preview release on September 12, 2024, marked a jump in reasoning capabilities. Models could follow long data flows and spot subtle logical flaws.Stronger Code Generation
Pass@1 improved markedly, raising single‑shot correctness. Harness and rule generation became less brittle and required fewer repair iterations.Maturing Agent Frameworks
LangChain’s first stable release (January 8) made “agents with tools” a practical engineering choice. Claude 3.5 (June 20) brought a model tuned for agentic workflows. LangGraph (August 1) simplified orchestration for complex agent graphs.
The Persistence of Code Classification
The code‑classification paradigm remained popular in 2024; many papers were still published in that space. As agentic paradigms emerged, much of this work began to look dated, though many of its components carried forward:
- Multi‑agent and multi‑role designs:
Multi‑Role Consensus through LLMs Discussions for Vulnerability Detection had “tester” and “developer” roles debate classification results. LLM‑SmartAudit used four roles—ProjectManager, Counselor, Auditor, Programmer—to collaborate on classification. The underlying idea—multi‑agent consensus—was later reused in agentic systems with greater impact. - Knowledge and prompt engineering:
Vul‑RAG used knowledge‑level retrieval augmentation; works on chain‑of‑thought prompting, DLAP, GRACE (CPG‑enhanced inputs), and SCALE (LLM‑generated comments plus AST) all contributed techniques—RAG, CoT, structured inputs—that remain useful today. - Fine‑tuning:
M2CVD combined CodeBERT and GPT; RealVul (EMNLP 2024) and VulLLM (ACL 2024 Findings) explored tuning strategies, yielding solid performance in narrow settings.
But the fundamental limitation did not change: classification treats a potentially tool‑using, environment‑interacting agent as a static function.
LLM‑Augmented Traditional Tools: Still the Right Direction
This line of work continued to deliver real wins.
Fuzzing
Google OSS‑Fuzz’s Leveling Up Fuzzing (Nov 2024) was a milestone: LLM‑generated fuzz harnesses, an agent loop to fix compiler errors, and LLM‑based crash triage. Across 272 C/C++ projects it added 370k+ new lines of covered code and found 26 new vulnerabilities, including CVE‑2024‑9143, a 20‑year‑old bug in OpenSSL. Code generation quality and reliability had finally reached a level where these systems produced tangible results at scale.
LIFTFUZZ (CCS 2024) used LLMs to generate assembly‑level tests for binary lifters, finding bugs in LLVM, Ghidra, and angr. ProphetFuzz (CCS 2024) had LLMs predict risky combinations of configuration options and, in 72 hours of fuzzing, found 364 vulnerabilities and obtained 21 CVEs.Static analysis
LLMDFA (NeurIPS 2024) was a compiler‑agnostic data‑flow analysis framework that decomposed problems into sub‑tasks, used LLMs to synthesize code that calls external tools, and leveraged tree‑sitter to reduce hallucinations, achieving 87.10% precision and 80.77% recall. IRIS combined LLMs with CodeQL for source/sink identification and false‑positive reduction. Enhancing Static Analysis for Practical Bug Detection (ACM PL 2024) used LLMs to filter UBITect results. SmartLLMSentry had LLMs generate vulnerability‑detection rules that were then executed by rule engines.
The common insight: LLMs are great at semantics and pattern recognition; classic tools are great at precise program analysis. Joining them yields more than the sum of their parts.
The First Agentic Auditors
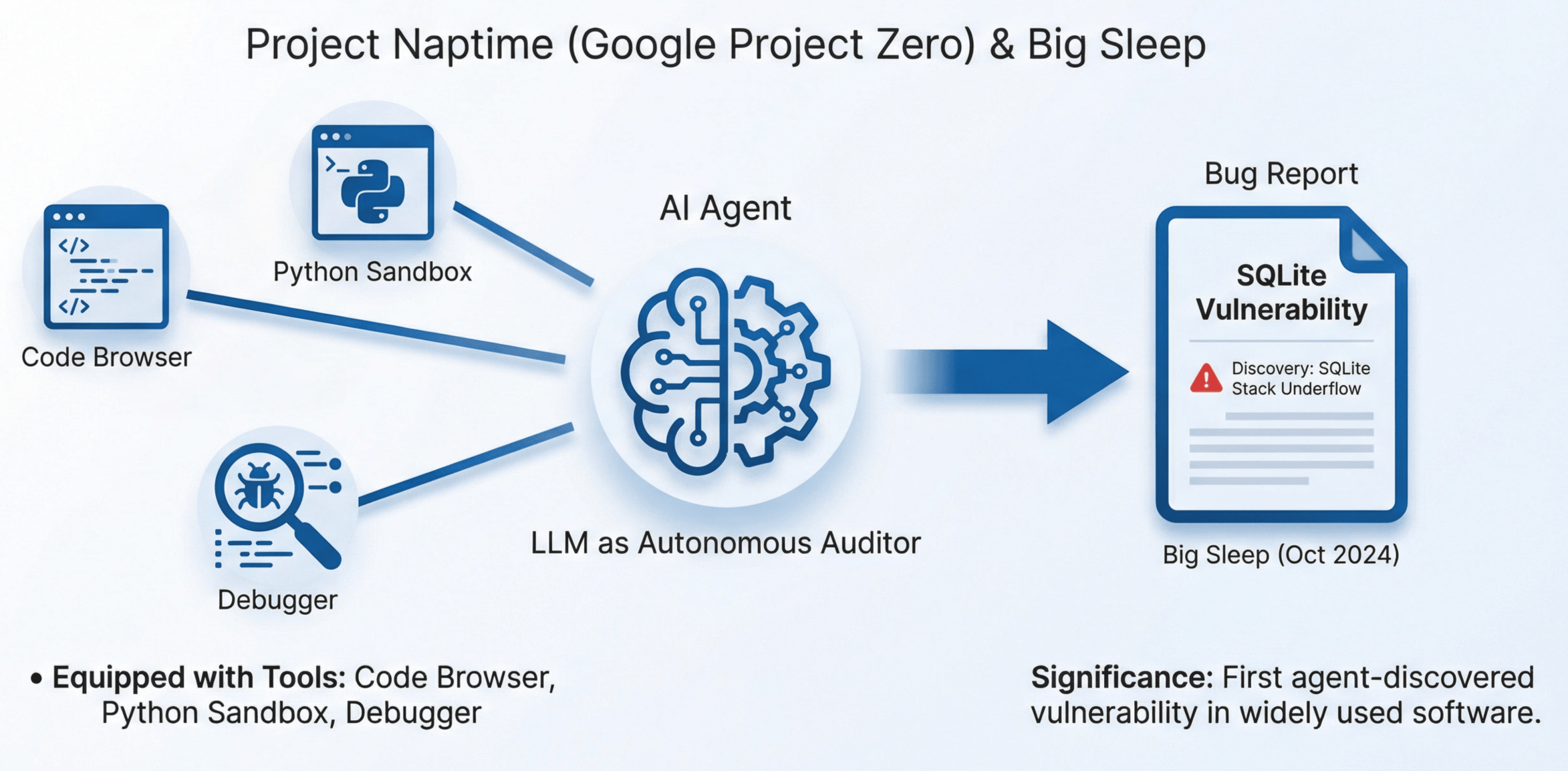
The most forward‑looking work in 2024 came from Google Project Zero:
- Project Naptime (June 2024) gave an LLM three tools: code browsing, a Python sandbox, and a debugger. The LLM proposed security hypotheses and systematically tested them, focusing on variant analysis. This was the first time an LLM was formally positioned as an autonomous auditor—not a classifier, not a sidekick to traditional tools, but an active explorer that forms and tests hypotheses.
- From Naptime to Big Sleep (October 2024) used this approach to find an exploitable stack underflow in SQLite—not via classification, not via fuzzing augmentation, but via LLM‑driven code auditing: understand code, hypothesize vulnerabilities, call tools, confirm the bug.
These papers correctly anticipated that agentic auditing would become the next main battleground—a prediction that 2025 would validate.
The 2024 Takeaway
The main lesson of 2024: in times of paradigm transition, spotting and aligning with the new paradigm matters more than optimizing the old one.
- Code‑classification work continued to refine metrics and components but was increasingly boxed in by its framing.
- LLM‑augmented fuzzing and static analysis delivered real‑world impact and remained valuable in 2025.
- Naptime and Big Sleep pointed the way to agentic auditing as the next dominant paradigm.

2025: The Agent Era — A New Default Paradigm
Key Changes in 2025 LLMs
In 2025, LLMs crossed a qualitative threshold:
- On February 24, Anthropic released Claude 3.7 and Claude Code, making long‑horizon planning, tool orchestration, and self‑correction standard capabilities. Models could decide their next steps, choose tools, and adapt strategies based on feedback.
- On May 15, Cursor 0.5 added Background Agent support. Agentic development at scale became routine; developers got used to delegating complex tasks to AI.
- Reasoning depth improved again: models could perform multi‑step security analysis, follow cross‑function data flows, and reason about implicit security assumptions. On many codebases, code‑understanding quality approached that of human experts.
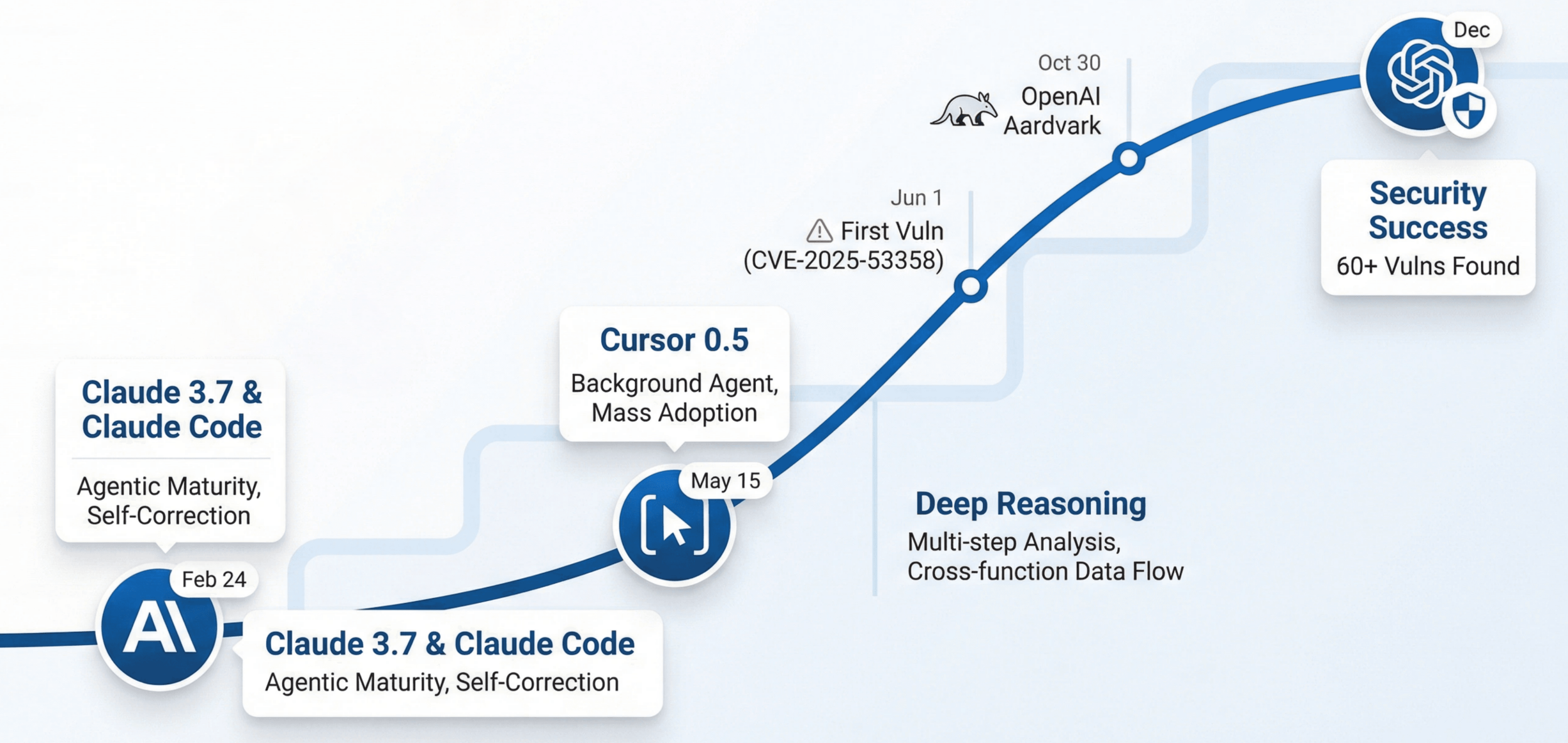
On June 1, 2025, our system found its first CVE, CVE‑2025‑53358: an arbitrary file‑read vulnerability in kotaemon, a 24k‑star RAG toolkit.
On October 30, OpenAI released Aardvark and formally entered the vulnerability‑discovery space.
By December 2025, we had crossed 60 vulnerabilities discovered in the wild.
A Clearer Landscape
By the end of 2025, the landscape looked roughly like this:
- Agentic code auditing became the mainline paradigm: LLMs act as auditors, control tools, and iteratively refine hypotheses.
- LLM‑augmented fuzzing and static analysis remained powerful and complementary.
- Code classification still had value as a sub‑component, but was no longer the research frontier.
Agentic Code Auditing at Scale
Industry players embraced agentic auditing in 2025:
- Anthropic’s Automated Security Reviews with Claude Code (August 2025) showcased LLM‑driven code review. SCONE‑bench (December 2025) evaluated LLM controllers that interact with smart‑contract environments to discover vulnerabilities.
- Snyk’s Human + AI: The Next Era of Snyk’s Vulnerability Curation (July 2025) used LLM agents to vet new commits, augmented with RAG over a historical vulnerability corpus and web search for context.
- OpenAI’s Aardvark (October 2025) put OpenAI directly into automated vulnerability discovery.
Academia followed:
- ACTaint (ASE 2025) used LLM agents to identify sources/sinks and directly reason about taint flows in smart contracts, targeting access‑control bugs.
- Exploring Static Taint Analysis in LLMs (ASE 2025) built a dynamic benchmark framework to evaluate LLMs’ intrinsic taint‑analysis abilities.
Deeper Integration with Traditional Tools
LLMs continued to boost traditional tools:
Fuzzing
The DARPA AIxCC challenge produced multiple heavyweight systems. Trail of Bits’ Buttercup (August 2025), which placed second, used LLMs to generate both seeds and patches, discovering and fixing bugs in real open‑source projects. All You Need Is A Fuzzing Brain (September 2025), which placed fourth, used an LLM as a fuzzing orchestrator with CWE‑based prompting to steer input generation toward specific bug classes; it autonomously found 28 vulnerabilities (including 6 zero‑days) and successfully patched 14.deepSURF (IEEE S&P 2025) used LLMs to generate harnesses for complex Rust API interactions. Unlocking Low Frequency Syscalls in Kernel Fuzzing with Dependency‑Based RAG used LLMs to synthesize test seeds for low‑frequency syscalls and combined them with syzkaller for kernel fuzzing.
Static analysis
LLM‑Driven SAST‑Genius: A Hybrid Static Analysis Framework used LLMs to reduce Semgrep’s alerts from 225 to 20 (a 91% reduction) and even auto‑generated proof‑of‑concept exploits.
QLPro: Automated Code Vulnerability Discovery used LLMs to generate rules for source/sink identification and CodeQL queries; across 10 open‑source projects it found 41 vulnerabilities (compared to 24 for baseline CodeQL), including 6 previously unknown bugs, 2 of which were confirmed 0‑days.STaint (ASE 2025) used LLMs to detect second‑order vulnerabilities in PHP applications via bidirectional taint analysis. Artemis: Toward Accurate Detection of Server‑Side Request Forgeries (OOPSLA 2025) used LLMs to assist path‑sensitive, inter‑procedural taint analysis, finding 106 real‑world SSRF bugs in 250 PHP applications, including 35 new issues and 24 CVEs.
AutoBug (OOPSLA 2025) integrated LLM reasoning into symbolic‑execution constraint solving and showed that, with path decomposition, even small models on commodity hardware can perform effective analysis. Towards More Accurate Static Analysis for Taint‑style Bug Detection in the Linux Kernel (ASE 2025) used LLMs to reduce false positives from traditional tools like CodeQL and Suture.
Work Still Framed as Classification
Some 2025 papers remained within the classification framework:
- LLMxCPG (USENIX Security 2025) had LLMs generate CPG queries and slice code, then perform binary classification on the slices. Smarter slicing improves context for LLMs and does stretch the envelope of classification‑based methods, but the overall framing—“feed slice, get label”—remains. As agent costs drop, the relative importance of this approach will likely shrink, though its CPG‑based context selection could be reused by agents.
- Context‑Enhanced Vulnerability Detection Based on Large Language Model extracted abstract features (API calls, branch conditions, etc.) from program analysis and had LLMs classify those features. Again, the feature‑extraction components can feed into agentic systems.
- R2Vul: Learning to Reason about Software Vulnerabilities with Reinforcement Learning used RL‑based distillation to make a 1.5B‑parameter model approach the performance of a much larger LLM, which is practically useful for resource‑constrained deployments.
- Agent4Vul converted smart contracts into annotated text plus vector representations and trained a multimodal classifier—an interesting direction for representation learning even if the outer loop is still classification.
These works continue to contribute building blocks, but the paradigm of “input code, output label” is no longer the best way to exploit what modern LLMs can do.
What Remains Constant: Knowledge Engineering
Across all these shifts, one thing remained central: knowledge engineering.
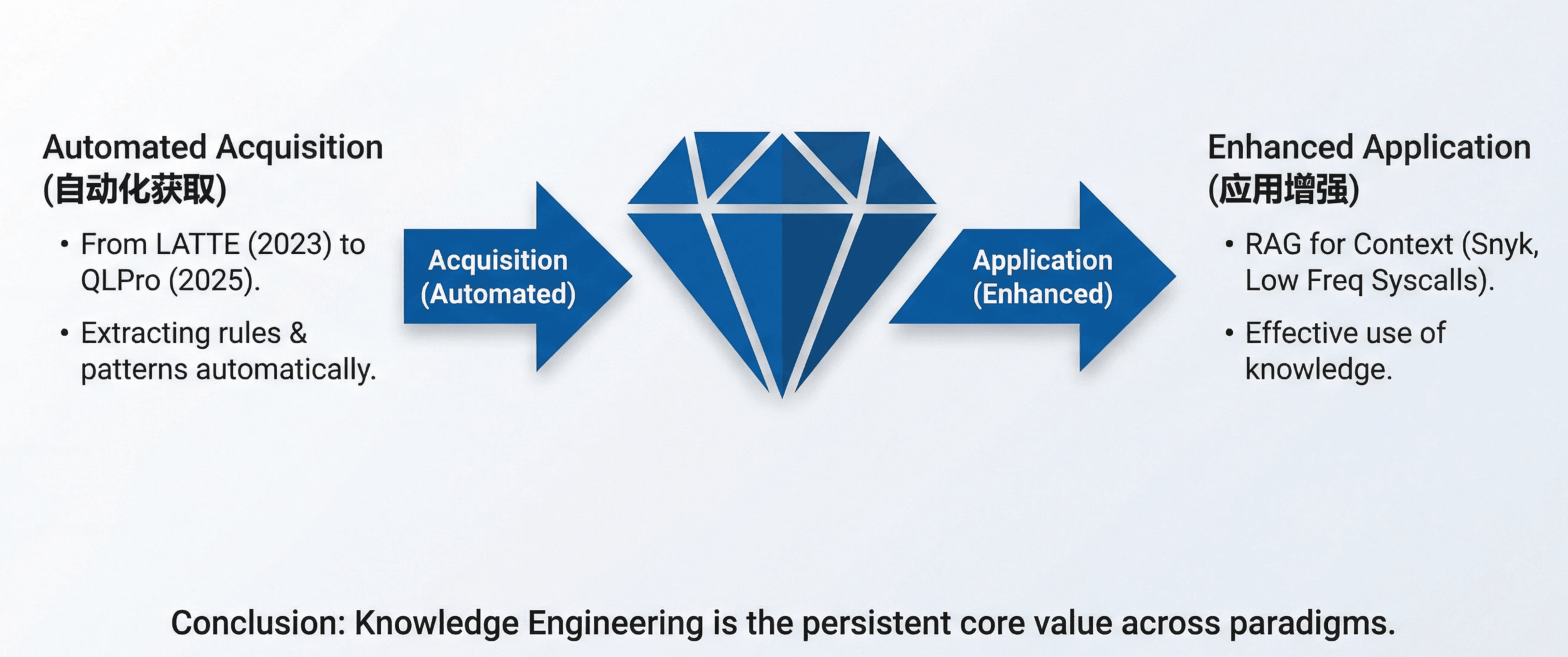
- Automating knowledge acquisition:
From LATTE (2023) extracting detection rules from documentation to QLPro (2025) generating CodeQL rules, the idea of using LLMs to ingest and structure expert knowledge has held up well. Vulnerability patterns, secure‑coding guidelines, API usage norms—these were once handwritten; now they can be mined. - Applying knowledge effectively:
Snyk’s use of historical vulnerability corpora with RAG, and Unlocking Low Frequency Syscalls’s dependency‑based RAG for seed generation, both show that getting the right knowledge into context is key, whether you are building assistive tools or agents.
The 2025 Takeaway
- Execution is cheap. Generating code, running tests, and iterating on fixes is now inexpensive enough that large‑scale automated auditing is realistic.
- Knowledge is the real bottleneck. Vulnerability patterns, best practices, and deep domain knowledge are scarcer than raw compute or model capacity. Powerful reasoning is useless if it is pointed at the wrong problems.
- Agents are the carriers of knowledge. Through tool use, LLMs can acquire, verify, and apply knowledge. Agents are not just executors; they are the interface between knowledge and action.
Part 3: Looking Forward — Execution Is Cheap, Paradigms Keep Shifting
When Execution Is Cheap, What Matters Is Deciding What to Do
By 2025, a profound shift was underway: the cost of executing and generating code was collapsing.
Three years ago, asking an LLM to write a complete fuzz harness meant days of back‑and‑forth debugging; today, a one‑shot compile‑success rate is dramatically higher. Three years ago, a large‑scale fuzzing campaign required carefully rationed cloud budgets; today, the same budget might buy 10× as much testing.
When “can we do it?” stops being the bottleneck, the hard question becomes: “What should we do?” Tools are readily available; the differentiator is direction. Whoever answers that question better will win the next round.
Seeing Direction Matters More Than Working Hard
Base models are still improving. They are getting stronger and cheaper—but at the same time, the half‑life of a paradigm is shrinking.
The harsh implication: the project you start today might be obsolete by the time you finish, because the underlying paradigm has moved on. A team that spent 2023 hand‑tuning features for a classifier might find, by late 2024, that agentic auditing has made that line of work far less relevant. The problem is not that the techniques are “bad”; it is that the frame is outdated.
This makes direction‑finding scarcer than execution capacity. Three questions become central:
- What remains invariant as AI changes?
- Where is the next paradigm likely to move?
- Which investments will survive paradigm shifts and continue to compound?
Short Term: Agent Orchestration Is Still a High‑Leverage Frontier
As base models converge in capability, how large can the gap between two agents built on the same model be?
Large—as large as the gap between a human and a dog.
With the same Claude 4.5, a poorly designed agent might choke on anything larger than a toy project, while Cursor has shown that a carefully orchestrated system can run for over 1 weeks and build a one‑million‑line browser from scratch. The difference is not the model; it is orchestration.
Questions that now dominate:
- How do you design the toolbox?
- How do multiple agents coordinate?
- How do you construct feedback loops?
- What does a robust error‑recovery strategy look like?
These engineering choices set the upper bound of system capability. In a world where base models are nearly commoditized, orchestration quality is one of the highest‑leverage levers you have.
Longer Term: Continual Learning Will Reshape the Agent Paradigm
Current agents share one fundamental limitation: they do not really learn over time.
Humans get better at a task by doing it repeatedly. After fixing ten SQL injection vulnerabilities, the eleventh often jumps out at you. Today’s agents behave in the opposite way: as the conversation grows and context balloons, they often get worse. Longer context does not make the model smarter; it tends to make it more confused.
This is why continual learning is such an active research topic. Whether solved via external knowledge bases and better context management, or via architectural changes in the models themselves, a breakthrough here would be transformational.
Imagine an agent that:
- has audited a hundred projects and has tacit knowledge of common vulnerability patterns
- remembers pitfalls from similar codebases last week
- has empirical priors for which warnings are usually false positives and which are likely gold
Such an agent would be fundamentally different from today’s “stateless across sessions” behavior.
Once we solve continual learning, the design of agents will have to change; the paradigm will shift again.
Where Are the Limits of AI in Vulnerability Discovery?
From 2022 to 2025, we saw three major paradigm shifts:
- LLMs as code classifiers
- LLMs augmenting fuzzers and static analyzers
- LLMs as autonomous, tool‑using agents
Each pushed the frontier outward.
Where are the current boundaries?
- Depth of global understanding is still limited. Even with million‑token windows, models do not yet grasp the global state of a complex codebase as deeply as a human expert. They can “read everything,” but that does not mean they truly understand cross‑cutting invariants.
- Domain knowledge scarcity is real. For emerging protocols, new hardware features, and rare bug classes, training data is thin. In such regimes, we still need carefully engineered prompts, RAG, and curated knowledge bases to activate relevant knowledge and suppress hallucinations. Knowledge engineering is especially valuable at these edges.
Crucially, though, these are engineering constraints, not fundamental limits.
Path explosion once looked like a “fundamental” limit for symbolic execution, yet we now use LLMs to guide selective path exploration and partially sidestep it. Context length once looked like a “fundamental” limit for transformers; we now routinely use hundred‑thousand‑token contexts. Technical obstacles tend to move from “impossible” to “merely hard.”
With continued progress in model capability, tooling integration, knowledge accumulation, and possibly new AI architectures, the boundary of what AI can do in vulnerability discovery will keep expanding.
AGI has a non‑trivial chance of becoming real.
And so does an automated vulnerability‑discovery system that rivals human experts. Maybe not next year, maybe not the year after—but it is very likely on its way.
Postscript: In February 2026, Anthropic's Claude Opus 4.6 automatically discovered over 500 zero-day vulnerabilities during internal red team testing, further validating the core thesis of this article—that the capability boundaries of AI in automated vulnerability discovery are rapidly expanding. For a detailed analysis of this event, see What Do Opus 4.6's 500 Zero-Days Mean for Us?.
Closing Thoughts
The last three years carry a clear message: the rules of the game are changing fast.
The return profile of research is changing with it. Last year’s state of the art may no longer be optimal this year, because the underlying paradigm has shifted. In this environment, understanding trends and anticipating paradigm shifts matters more than marginally improving metrics within an aging frame. Focusing on what actually works in practice, rather than just what gets published.
Our 60+ vulnerabilities did not come from pressure to publish; they came from repeatedly asking one question: what actually works in the wild?